Chapter 5 Project G: Handwriting (& Signatures)
The handwriting project has four major focuses:
data collection
computational tools
statistical analysis
- glyph clustering
- closed set modeling for writer identification
- (Arabio) point decomposition triangulation method
- open set modeling for writer identification from distribution of glyphs in clusters
communication of results
5.1 Data Collection
We are conducting a large data collection study to gather handwriting samples from a variety of participants across the world (most in the Midwest). Each participant provides handwriting samples at three sessions. Session packets are prepared, mailed to participants, completed, and mailed back. Once recieved, we scan all surveys and writing samples. Scans are loaded, cropped, and saved using a Shiny app. The app also facilitates survey data entry, saving that participant data to lines in an excel spreadsheet.
As of September 2019, Marc and Anyesha are the primary contacts for the study. Phase 2 recruiting is underway.
The first 90 complete writers were published: > Crawford, Amy; Ray, Anyesha; Carriquiry, Alicia; Kruse, James; Peterson, Marc (2019): CSAFE Handwriting Database. Iowa State University. Dataset. https://doi.org/10.25380/iastate.10062203.
Anyesha and I worked on a variety of data quality checks and batch processing prior to publication. Scanner cuts a portion of the left side of the documents off sporadically. Survey date checks. Batch removal of header.

Figure 5.1: Batch process samples: rotate 0.05 degrees, turn black line pixels white, crop 450 pixels from top (under QR code), rename.
We hit a bump with the ISU Office for Responsible Research (ORR).
They had concerns with the demographic variables we collected on the surveys and wanted to publish. We “negotiated’’ and settled on the following survey information.
A data article was accepted at Data in
Brief.
Crawford, A., Ray, A., & Carriquiry, A. (2020). A database of
handwriting samples for applications in forensic statistics. Data in
brief, 28, 105059.
Crawford, A., Ray, A., & Carriquiry, A. (2020). A database of handwriting samples for applications in forensic statistics. Data in brief, 28, 105059.

5.2 Software
5.2.1 handwriter
handwriter is a developmental R package hosted at
https://github.com/CSAFE-ISU/handwriter. It is our major computational
tool for the project. The package takes in scanned handwritten documents
and the following are performed:
- Binarize. Turn the image to pure black and white.
- Skeletonize. Reduce writing to a 1 pixel wide skeleton.
- Break. Connected writing is decomposed into small manageable pieces called glyphs. Glyphs are graphical structures with nodes and edges that often, but not always, correspond to Roman letters, and are the smallest unit of observation we consider for statistcal modelling.
- Measure. A variety of measurements are taken on each glyph. See Section 4.2.1.
- (Optionally) Plot. Plot graphs, words, lines, or the entire document

Figure 5.2: Connected text processed by handwriter. The grey background is the original pen stroke. Colored lines represent the single pixel skeleton with color changes marking glyph decomposition. Red dots mark endpoints and intersections of each glyph.
5.2.2 Shiny app
In addition to the R package handwriter, there is a shiny app that allows users to do end to end processing and analysis of handwriting documents. The shiny app includes:
Welcome
Figure 5.3: Users are welcomed and shown what they can do, as well as given contact info
Preprocessing
Figure 5.4: Users can rotate, crop, and mask parts of their image as part of preprocessing. These functions are the only functions in the shiny app which exist outside of handwriter
Plotting
Figure 5.5: Users can plot graphs, words, lines, or the entire document`-
Feature Exploration
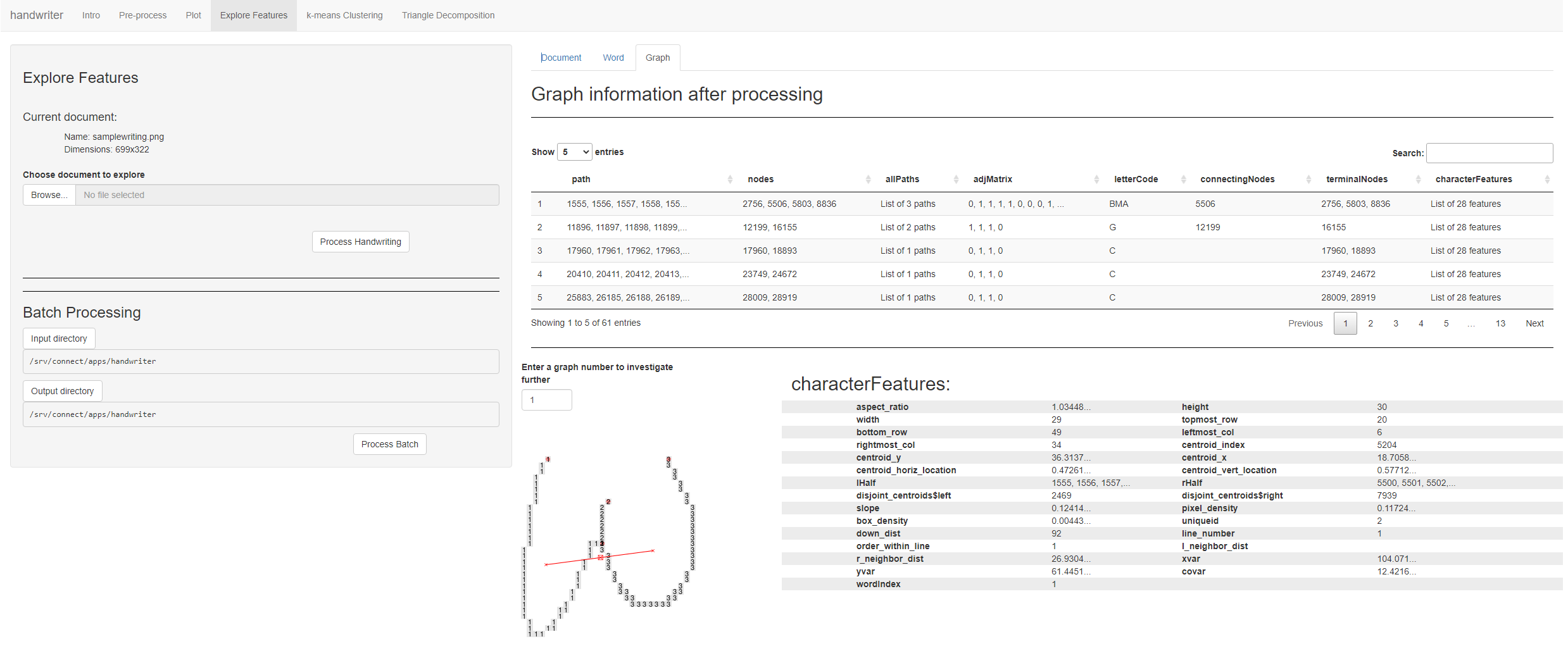
Figure 5.6: Users can explore features at a graph, word, or document level
k-means Clustering
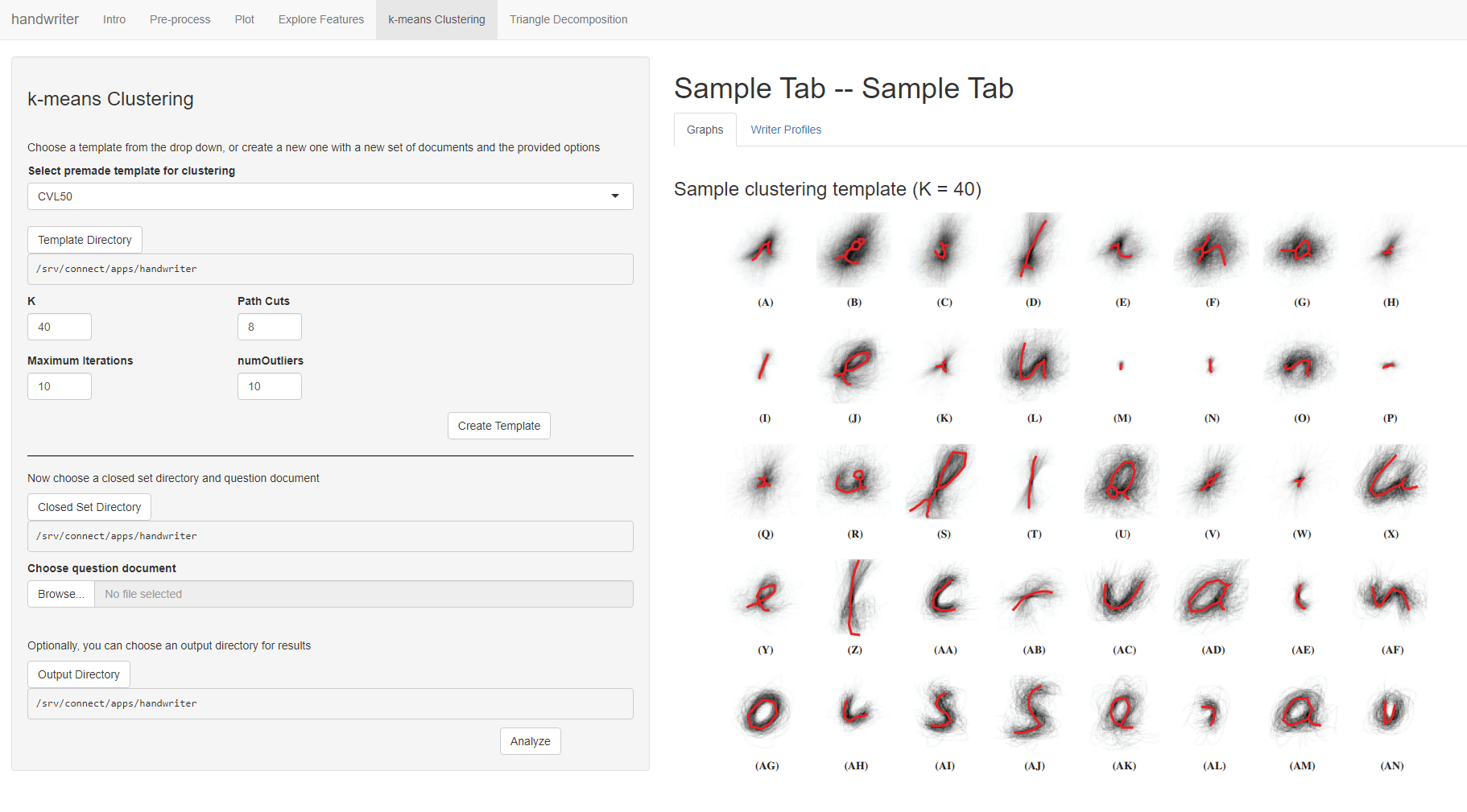
Figure 5.7: Users will be able to create a k-means clustering template or use a premade one, and then introduce a new known author set and question document
Triangle Decomposition
Figure 5.8: Users will be able to perform triangle decomposition on their document.
5.3 Statistical Analysis
5.3.1 Clustering
Paper submitted to ASA Statistical Analysis and Data Mining.

Rather than impose rigid grouping rules (the previously used ‘’adjacency grouping’’) we consider a more robust, dynamic \(K-\)means type clustering method that is focused on major glyph structural components.
Clustering algorithms require:
- A distance measure. For us, a way to measure the discrepancy between glyphs.
- A measure of center. A glyph-like structure that is the exemplar representation of a group of glyphs.
Glyph Distance Measure
We begin by defining edge to edge distances. Edge to edge distances are subsequently combined for an overall glyph to glyph distance.
Edge to edge distances:
Consider the following single edge glyphs, \(e_1\) and \(e_2\). Make \(3\) edits to \(e_1\) to match \(e_2\). The combined magnitude of each edit make the edge distance.
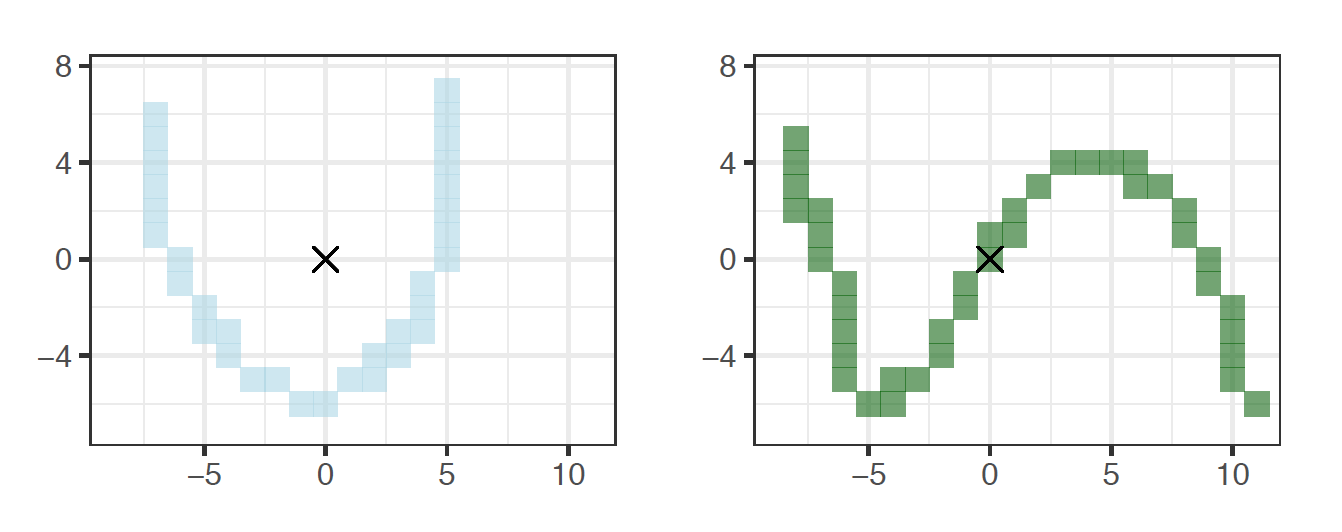
Figure 5.9: Two edges that are also glyphs, \(e_1\) and \(e_2\).
- Shift. Anchor to the nearest endpoint by shifting.
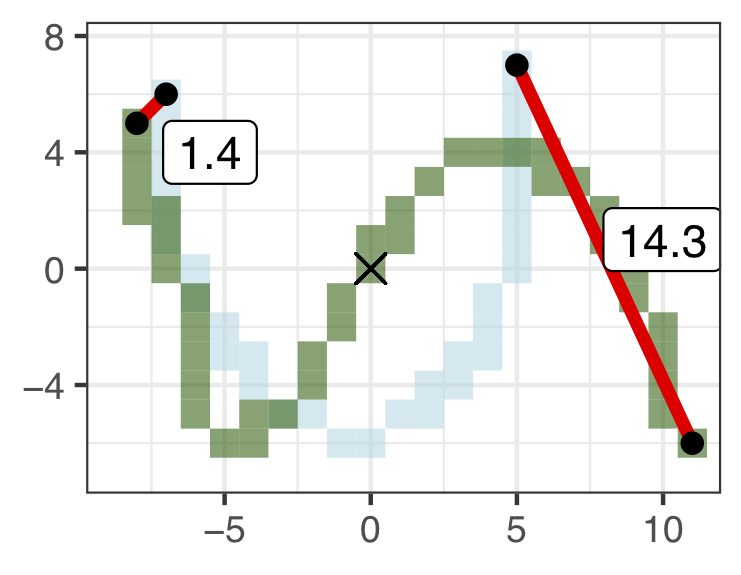
Figure 5.10: Shift = 1.4.
- Stretch. Make the endpoints the same distance apart.
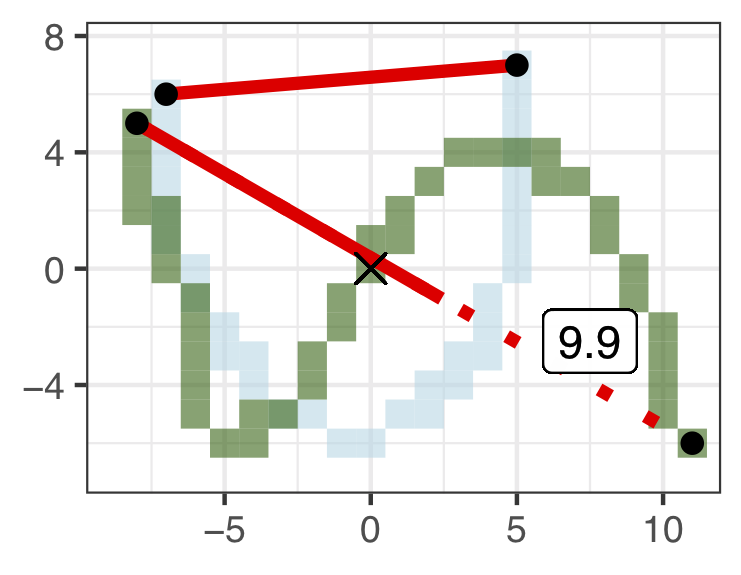
Figure 5.11: Stretch = 9.9.
- Shape. Bend and twist the edge using \(7\) shape points. Shape points are ‘’matched’’ and the distance between them is averaged to obtain the shape contribution to the distance measure.
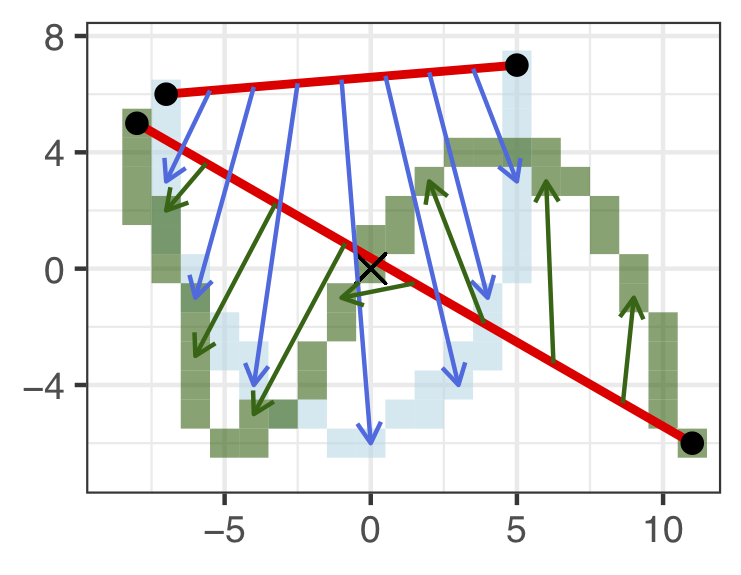
Figure 5.12: Shape Components.

Figure 5.13: Shape = 8.4.
Combine the three measurements for a final edge to edge distance. D\((e_1, e_2) = 1.4 + 9.9 + 8.4 = 19.7\).
For multi-edge glyphs get pairwise edge distances. Minimize total glyph distance using linear programming to match edges (sudoku). Down-weight edge distance contributions based on edge lengths. There are nuances associated with all of this. We must handle glyphs with differing number of edges, and consider the direction in which edges are compared (endpoint labels are arbitrary). All of this is addressed in detail in the paper.
Measure of glyph centers
Take the weighted average of endpoints, \(7\) shape points, and edge length.
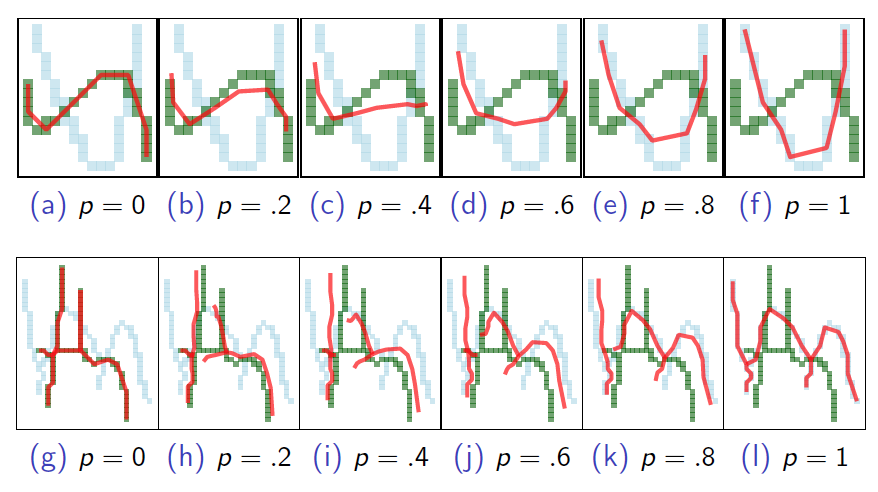
Figure 5.14: Weighted mean between two glyphs. p = weight on blue.
The mean of a set can be iteratively calculated by properly weighting each newly introduced glyph. For stability, the \(K-\)means algorithm finds the glyph nearest the mean and uses that as measure of cluster center.
\(K-\)means Algorithm for Glyphs
Implement a standard \(K-\)means 1 2 with handling of outlier observations. 3
Begin with fixed \(K\) and a set of exemplars. Iterate between the following steps until cluster assignments do not change:
- Assign each glyph to the exemplar it is nearest to, with respect to
the glyph distance measure.
- Calculate each cluster mean as defined. Find the exemplar nearest the cluster mean and use it as the new cluster center.
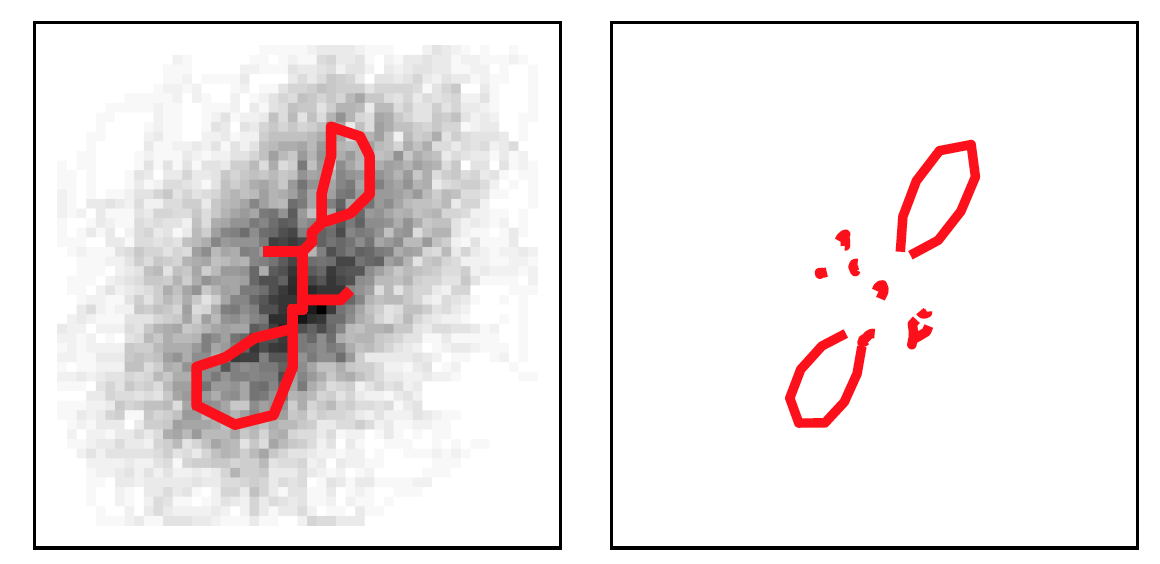
Figure 5.15: One of \(K=40\) Clusters. Exemplar & cluster members (left). Cluster mean (right).
Use one document from each training writer to cluster and obtain a template. Make cluster assignments for the remaining documents by finding the template exemplar each glyph is nearest to. Below is an example of data that arises from the clustering method.
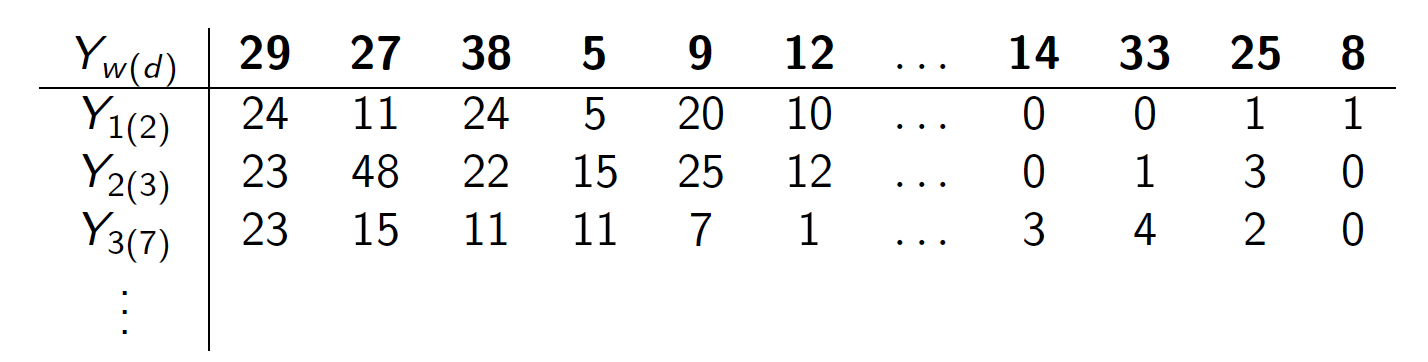
Figure 5.16: Data arising from the cluster grouping method. Cluster #’s ordered by most to least populated.
5.3.1.1 Outliers
During clustering, outliers are considered glyphs that are at least \(T_o\) distance units from cluster exemplars. The algorithm sets a ceiling \(n_o\) on the allowable number of outliers. Initially, we were going to ignore the outliers, but now they are considered the \(K+1\)th cluster and contribute information about writer.

Figure 5.17: Cluster of outliers.
5.3.1.2 CVL + CSAFE + IAM Template Development
Template development on:
1. CSAFE Handwriting Database, 25 documents.
2. Computer Vision Lab (CVL) Database, 25 documents.
3. IAM Handwriting Database, 50 documents.With the new template, we’ve made a few adjustments to the original algorithm and measurement tools:
Starting values.
Changes to the distance measurement to emphasize shape, and focus less on character size.
- \(\frac{1}{2}\times\) Stretch (straight line distance component, ~ size)
- 1 \(\times\) Shift (nearest endpoint)
- 2 \(\times\) Shape
- (ghost edge comparisons)\(^2\)
A sample template is picture below.
- 27 CVL documents (6 unique), 73 CSAFE documents (2 unique)
- Currently working on 20+ algorithm runs with a variety of starting values to select final template.
The final template.

Figure 5.18: Exemplars for the first 20 most populated clusters (according to training data, later). The red lines are not plotting correctly..

Figure 5.19: Exemplars for the first 20 least populated clusters (according to training data, later). The red lines are not plotting correctly..
5.3.1.3 Convergence of Clustering Template Algorithm
This section was written by Stephanie Reinders October 22, 2021.
Amy Crawford created a K-means type algorithm that groups graphs extracted from handwriting samples into clusters. See the previous sections for her summary of her work. I am in the process of using her clustering template creation code to create new templates on different training data.
As mentioned in the previous section, Amy’s K-means algorithm consists of two main steps: - ASSIGNMENT STEP: assign each graph to the nearest cluster - UPDATE STEP: calculate the new cluster center These two steps are repeated until the graph assignments don’t change or the maximum number of iterations is reached. (See the pseudo code below for a more detailed description of Amy’s K-means algorithm) If the algorithm reaches a place where the graph assignments no longer change, we say that the algorithm converged.
PSEUDO CODE: Current Clustering Template Algorithm:
Input:
K = number of clusters
graphs = n graphs from training handwriting samples
centers = K graphs to be used as starting cluster centers
Output:
centers = K final cluster centers
1. # Calculate distances
2. For each center c in centers
3. For each graph g in graphs
4. dist(c,g) = the graph distance between c and g
5. # Cluster assignment
6. For each graph g in graphs
7. assign(g) = the cluster to which g has the smallest distance in dist
8. # Calculate mean graph and update center
9. for each cluster k in K
10. sort the graphs in k from closest to k's center to farthest
11. mean_graph = first graph g in the sort list
12. remove the first graph from the sorted list
11. for each graph g in the sorted list
12. mean_graph = the average of mean_graph and g
13. c = graph in cluster k closest to mean_graph
14. Terminate if no center changed or if max iterations is reached. Otherwise repeat lines 1-13.Amy found that even on the same training data depending on the random seed used, some cluster templates don’t converge even after letting the algorithm run for ~24 hours. I have run into the same problem. Over the past week I have been trying to figure out why some templates don’t converge.
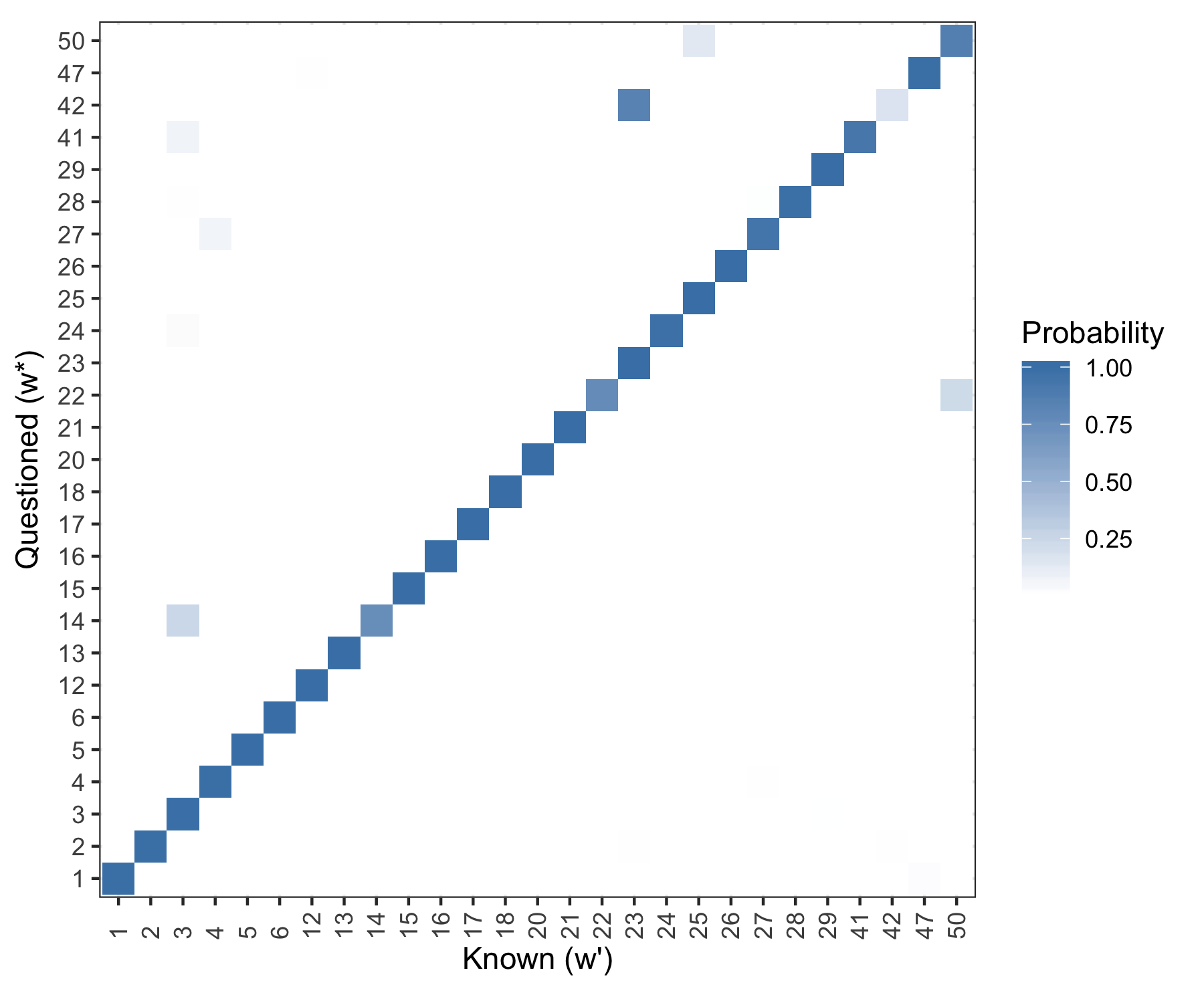
Figure 5.20: Posterior predictive results. Rows are evaluated independently and the probability in each row sums to one. Log Loss = 0.2013
5.3.2 Statistical Modeling
Model #1, Straw Man
Let,
- \(\boldsymbol{Y}_{w(d)} = \{Y_{w(d),1}, \dots, Y_{w(d),K}\}\) be the number of glyphs assigned to each cluster for document within writer, \(w(d),\) and
- \(\boldsymbol{\pi}_w = \{\pi_{w,1}, \dots, \pi_{w,K} \}\) be the rate at which a writer emits glyphs to each cluster.
- Here, \(K = 41\), \(d = 1,2,...,5\), \(w = 1,...,27\).
Then a hierarchical model for the data is \[\begin{array}{rl} \mathbf{Y}_{w(d)}\: &\stackrel{ind}{\sim} \:Multinomial(\boldsymbol\pi_{w}), \\ \boldsymbol{\pi}_w \:&\stackrel{ind}{\sim}\: Dirichlet(\boldsymbol{\alpha}),\\ \alpha_{1}, \dots, \alpha_{K}\: &\stackrel{iid}{\sim}\: Gamma(2, \:0.25). \label{model_line3} \end{array}\]
Posterior Predictive Analysis
For a holdout document of unknown source, \(w^*\),
Extract glyphs with and assign groups,
- \(\boldsymbol{Y}^*_{w^*}=\{Y_{w^*,1}, ... Y_{w^*,K}\}\)
Assess the posterior probability of writership under each known writer \(\boldsymbol\pi_{w}\) vectors.
- i.e. \(p(w^* = w^\prime|\boldsymbol{Y^*}, \boldsymbol{Y})\) for each writer \(w^\prime\) in the training data.
The posterior probability that the questioned document \(\boldsymbol{Y}^*_{w^*}\) belongs to writer \(w^\prime\) with respect to the closed set is, \[\begin{array}{rl} p(w^* = w^\prime|\boldsymbol{Y}^*, \boldsymbol{Y}) & \propto p(\boldsymbol{Y}^*| w^* = w^\prime, \boldsymbol{Y}) p(w^*=w^\prime | \boldsymbol{Y})\nonumber\\ & \propto p(\boldsymbol{Y}^*| w^* = w^\prime, \boldsymbol{Y}) \nonumber\\ & = \int p(\boldsymbol{Y}^*| \boldsymbol{\pi}_{w^\prime}) p(\boldsymbol{\pi}_{w^\prime}| \boldsymbol{Y}) d \boldsymbol{\pi}_{w^\prime}\nonumber\\ & \approx \frac{1}{M} \sum_{m=1}^M p(\boldsymbol{Y}^*| \boldsymbol{\pi}^{(m)}_{w^\prime}) , \mbox{ where } \boldsymbol{\pi}^{(m)}_{w^\prime} \sim p(\boldsymbol{\pi}_{w^\prime}|\boldsymbol{Y}) \nonumber \end{array}\]
for MCMC iterations \(m = 1, \dots, M\). Then, for a given iteration \(m\),
\[ p(\boldsymbol{Y}^*| \boldsymbol{\pi}^{(m)}_{w^\prime}) = p_{w^\prime}^{(m)} = \frac{Mult(\boldsymbol{Y}^*; \boldsymbol{\pi}_{w^\prime}^{(m)})}{\sum_{w_i = 1}^{27}Mult(\boldsymbol{Y}^*; \boldsymbol{\pi}_{w_i}^{(m)}) }. \nonumber \] Calculate the quantitity for each known writer \(w^\prime = w_1, \dots, w_{27}\) in training set to get \[ \boldsymbol{p}^{(m)} = \{p_{w_1}^{(m)}, ..., p_{w_{27}}^{(m)}\}, \] and compute summaries over the MCMC draws, \[ \boldsymbol{\bar{p}} = \{\bar{p}_{w_1},...,\bar{p}_{w_{27}}\}. \]
Results
If we use a single holdout document for each writer (doc 4). The \(\boldsymbol{\bar{p}}\) vector as given above is shown graphically for each holdout document (the rows).
Figure 5.21: Posterior predictive results. Rows are evaluated independently and the probability in each row sums to one. Log Loss = 0.2013
We can use a cross validation routine to estimate error. For each writer, shuffle the order of their body of documents. For the first fold we holdout the first document for testing, for the second fold we hold out the second document for testing, etc.. This yields 6 results analogous to that of the figure above.
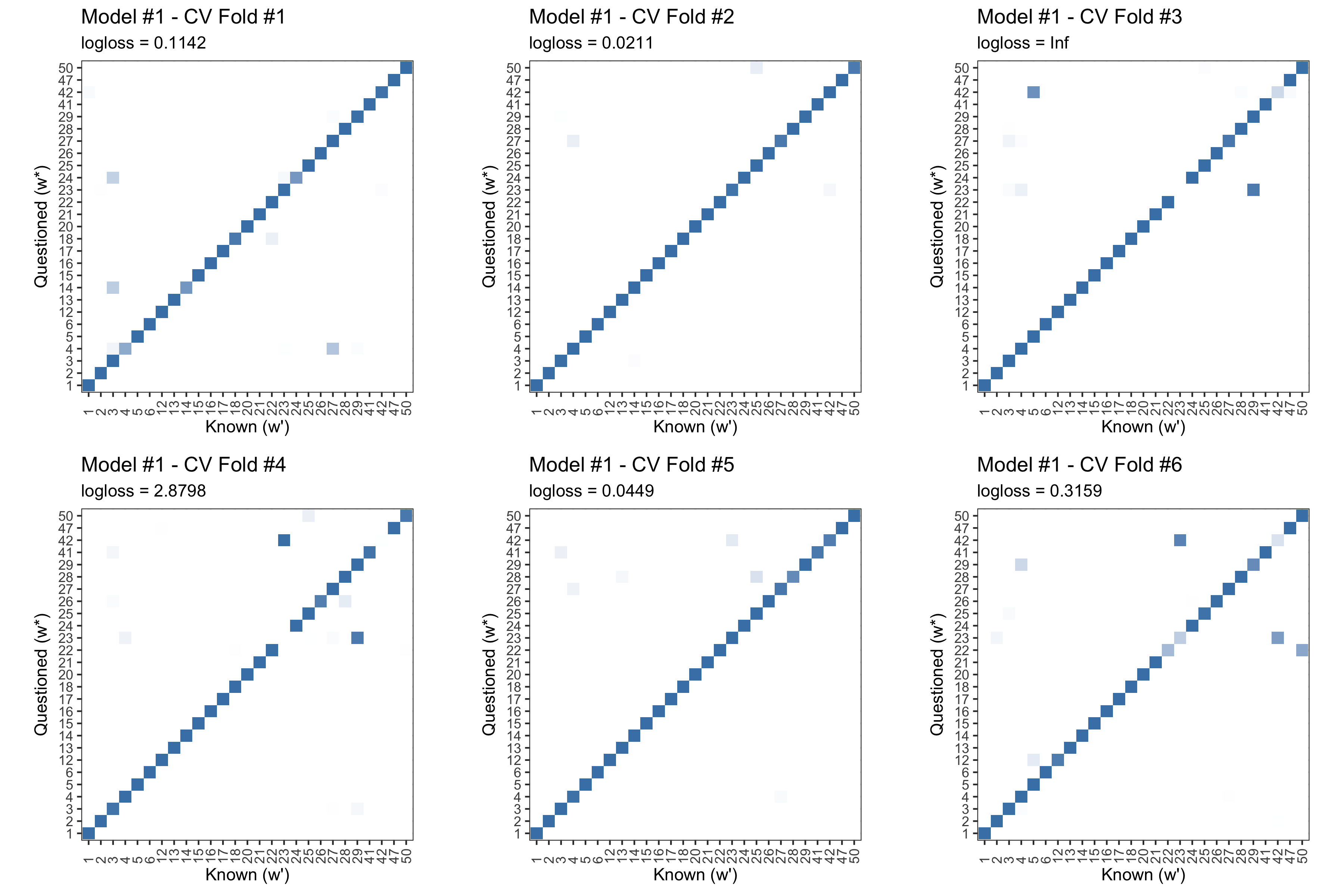
Figure 5.22: Posterior predictive results for each fold of the CV routine outlined above. Log Loss is clearly not a great summary of performance.
Evaluating Over-/Under-dispersion (Writer Variability Index)
With a count data model it is important to investigate the presence of
over- and under-dispersion. An index of intra-writer variability with
respect to a model.
- Multivariate Generalized Dispersion Index (GDI) of Kokonendji and Puig4.
- Relative Dispersion Index (RDI) = \(\frac{\mbox{writer data GDI}}{\mbox{model simulated GDI}}.\)
- High RDI \(\implies\) data over-dispersion and high sample to sample variability.
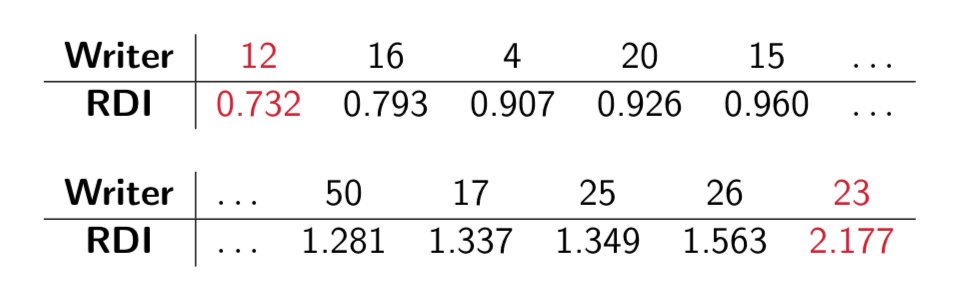
Figure 5.23: RDIs for the 27 CVL writers under Model #1.
High RDI \(\implies\) data over-dispersion & high sample to sample variability (in the sense of glyph cluster membership rates).

Figure 5.24: Handwriting Samples from Writer #12. Notice the repeated patterns in letters ‘a’, ‘e’, ‘f’, ‘g’, ‘h’, ‘t’, etc. across samples.
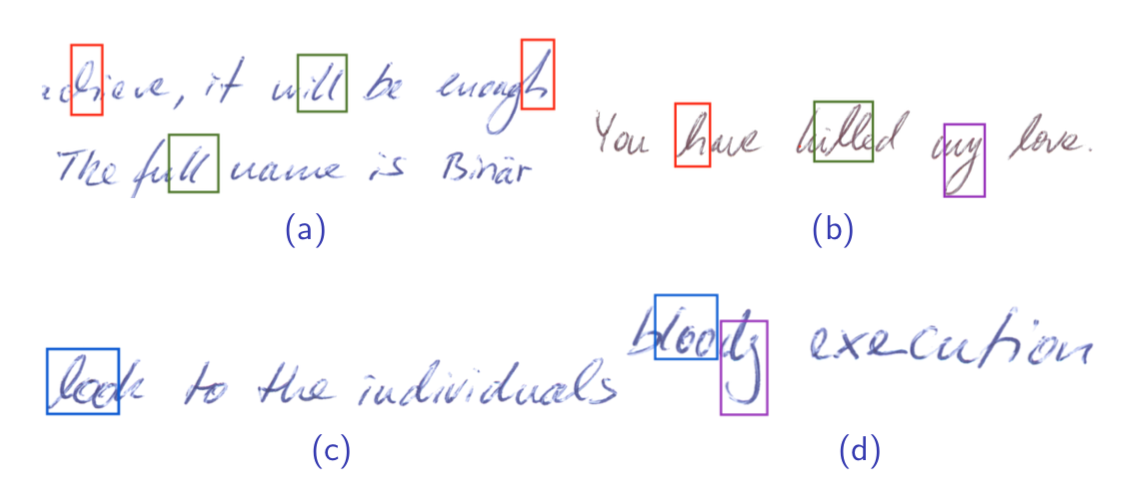
Figure 5.25: Handwriting Samples from Writer #23. Note the red ’h’s, green ’ll’s, purple terminal ’y’s, and blue ’loo’s
Model #2, Mixture
There seem to be greatly varying shapes in the relative frequency of cluster fill. We think maybe a more flexible Dirichlet distribution is warranted.
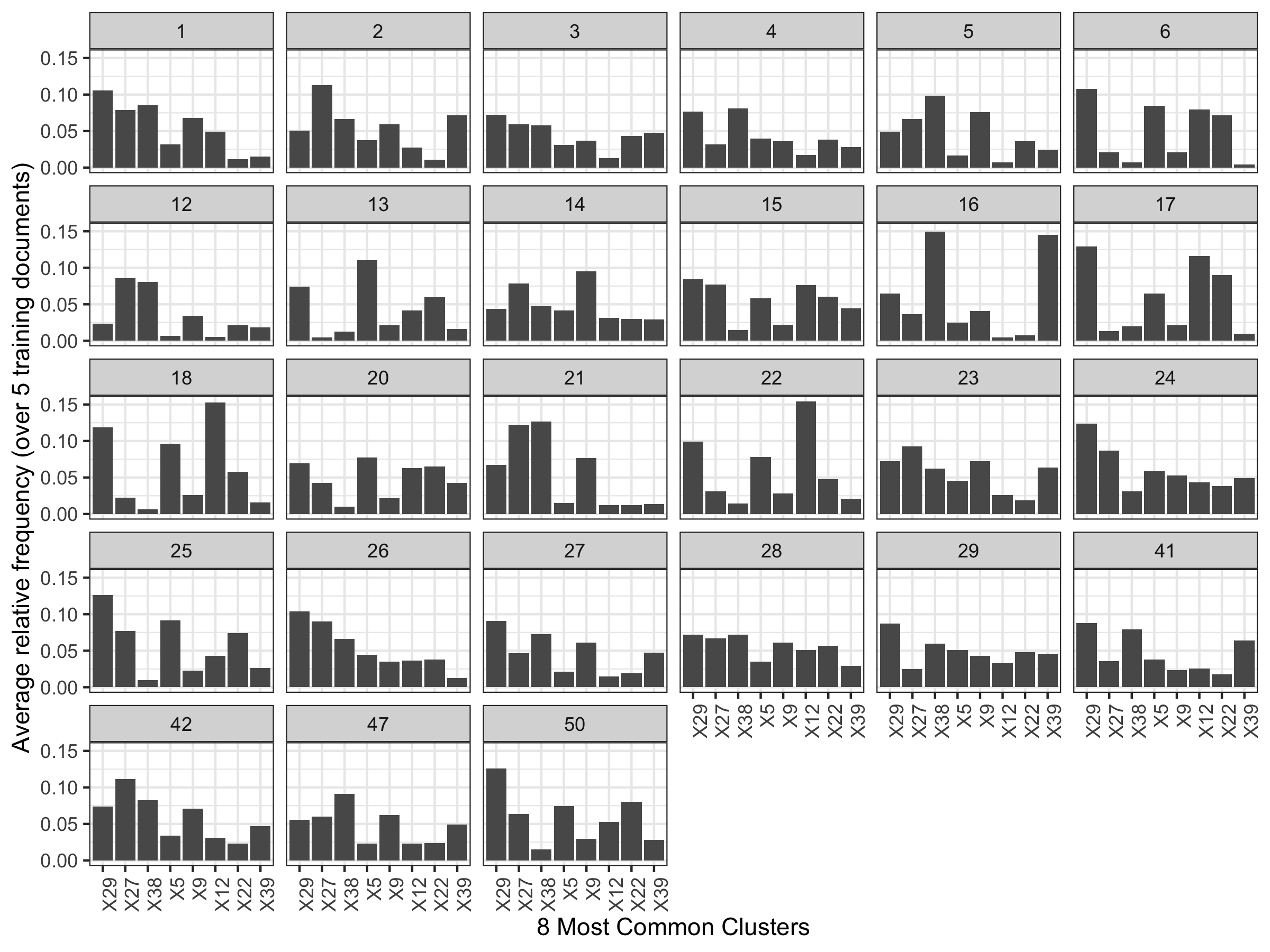
Figure 5.26: Average relative frequency of cluster fill for the 8 most common clusters. Notice writers 12/21 and 6/17/18.
Add flexibility to the original model by including a mixture component in the Dirichlet parameter space.
\[\begin{array}{rl} \mathbf{Y}_{w(d)} | \boldsymbol\pi_{w}, w\: &\stackrel{ind}{\sim} \:Multinomial(\boldsymbol\pi_{w}), \\ \boldsymbol{\pi}_w|\boldsymbol{\alpha},\boldsymbol{\beta}, \rho_w \:&\stackrel{ind}{\sim}\:Dirichlet(\rho_w \: \boldsymbol{\alpha}+ (1-\rho_w) \: \boldsymbol{\beta}), \\ \alpha_{k}, \: \beta_{k} \: &\stackrel{iid}{\sim}\: Gamma(2, \: 0.25) \:\: \mbox{ for } k > 3, \\ \rho_w\: & \stackrel{iid}{\sim}\: Beta(1,1) \end{array}\]
Label Switchin Issues.
The model is non-identifiabile. We need to either place constraints on
the parameter space to exclude the possibility of a second mode apriori,
or estimate the posterior in both modes and post-process for label
reassignment after. This has been resolved (?) by placing constraints on
the first three elements of \(\alpha\) and \(\beta\) with moderately
informative priors.
\(\mathbf{\alpha_1 < \beta_1}\), \(\quad\) \(\alpha_1 \sim Gamma(2, 0.25) \:\: \& \:\: \beta_1 \sim Gamma(4, 0.25)\)
\(\mathbf{\alpha_2 > \beta_2}\) , \(\quad\) \(\alpha_2 \sim Gamma(4, 0.25) \:\: \& \:\: \beta_2 \sim Gamma(1, 0.25)\)
\(\mathbf{\alpha_3 > \beta_3}\) , \(\quad\) \(\alpha_3 \sim Gamma(4, 0.25) \:\: \& \:\: \beta_3 \sim Gamma(1, 0.25)\)
## Error in library(tidyverse): there is no package called 'tidyverse'## Error in gather(., key = "GammaDist", value = "value", -x): could not find function "gather"Results
The mixing component gives insights into writing style.
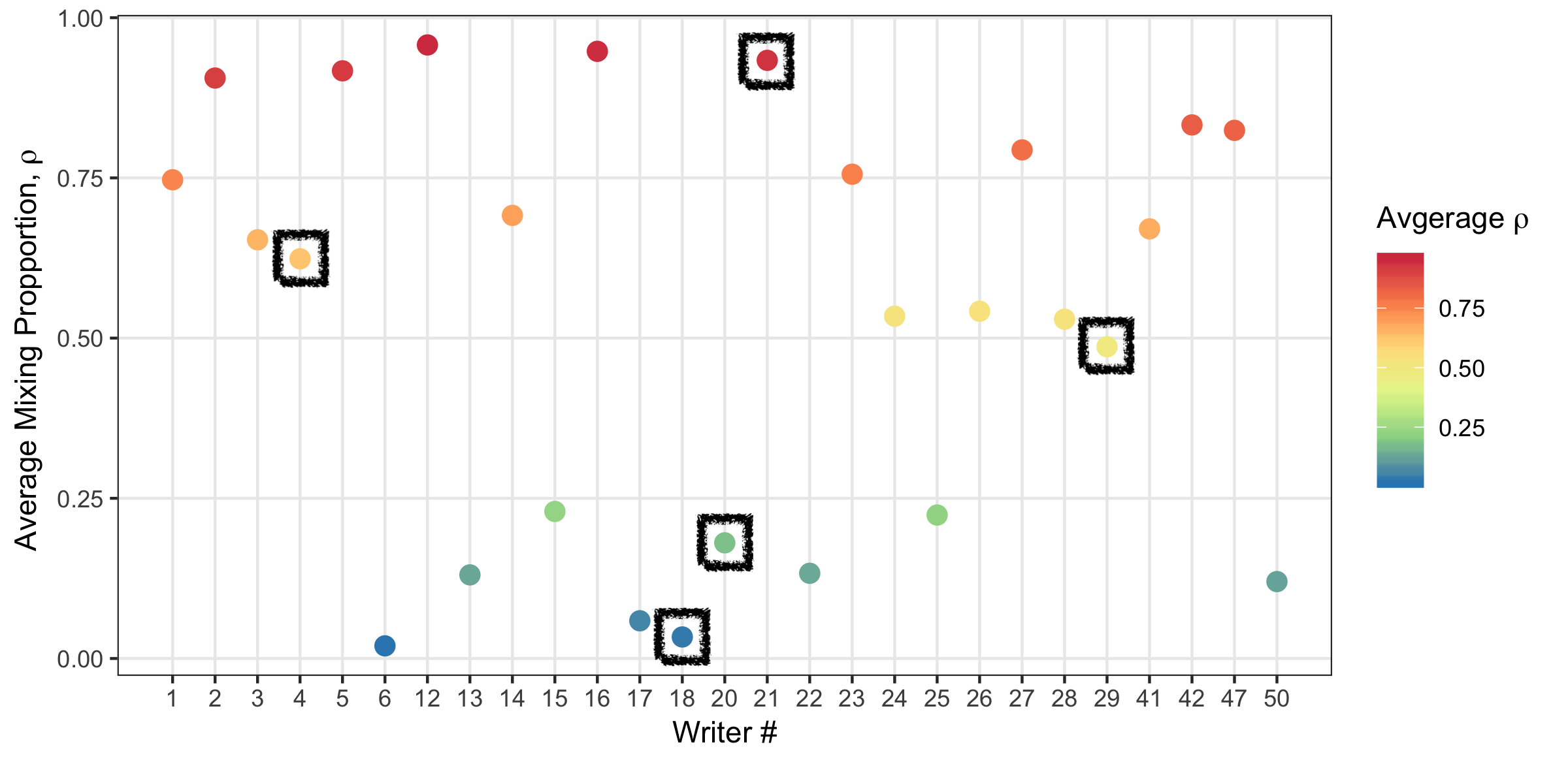
Figure 5.27: Average ho_w value for each writer.

Figure 5.28: Writing samples in a variety of styles based on the mixing parameter. From top to bottom, writer #’s 21, 4, 29, 20, 18.
Evaluate the posterior probability of writership for each of the holdout documents.
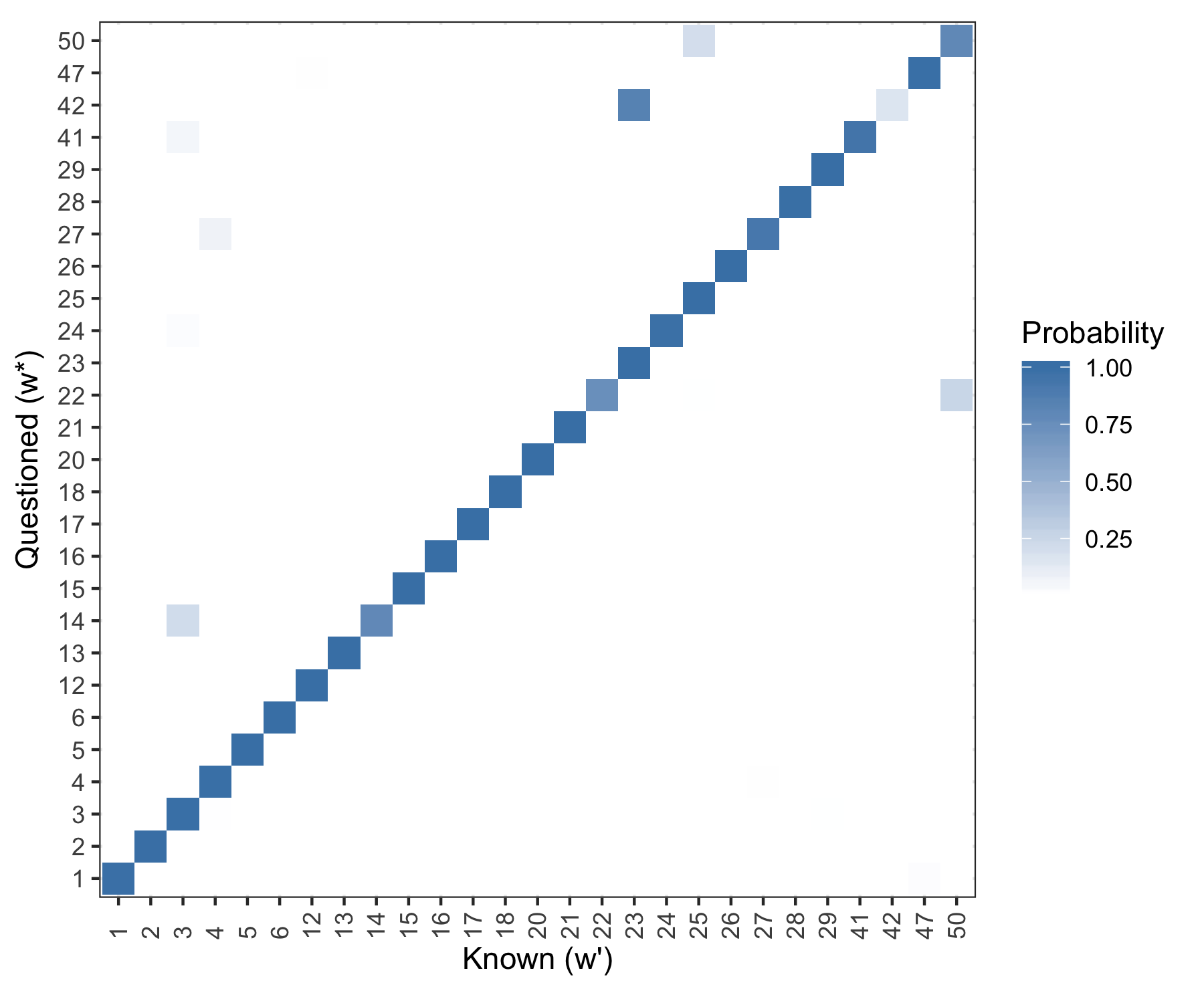
Figure 5.29: Posterior predictive results. Rows are evaluated independently and the probability in each row sums to one. Log Loss = 0.2078
5.3.2.1 Model #2, CSAFE + CVL (not most recent) Template
The following analysis was done for the first 20 CSAFE writers.
- Training docs: s01_pLND_r01, s01_pLND_r03, s01_pWOZ_r02,
s01_pPHR_r03
- Testing doc: s01_pLND_r02
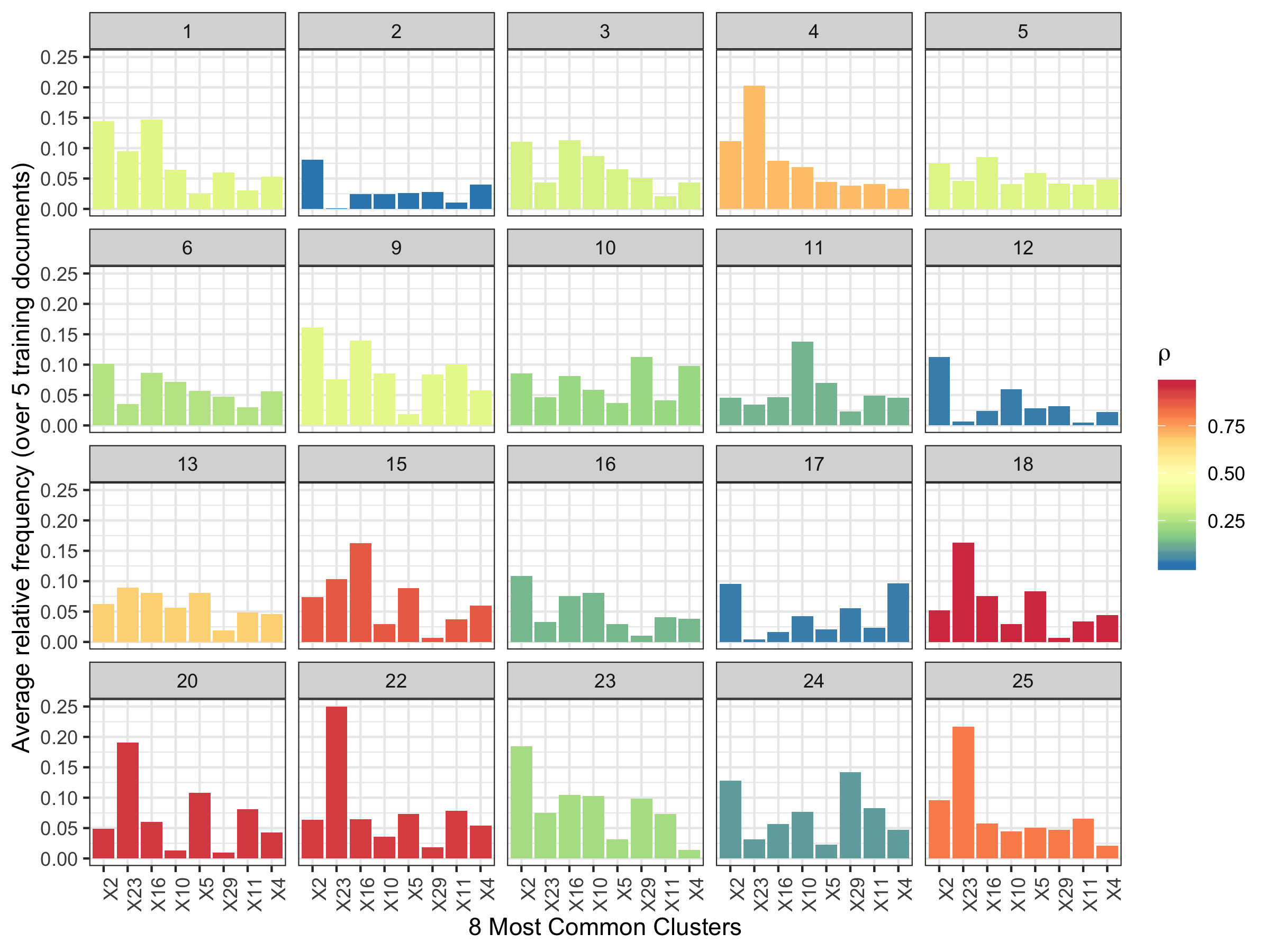
Figure 5.30: Average relative frequency of cluster fill for the 8 most common clusters.
Posterior probability results.
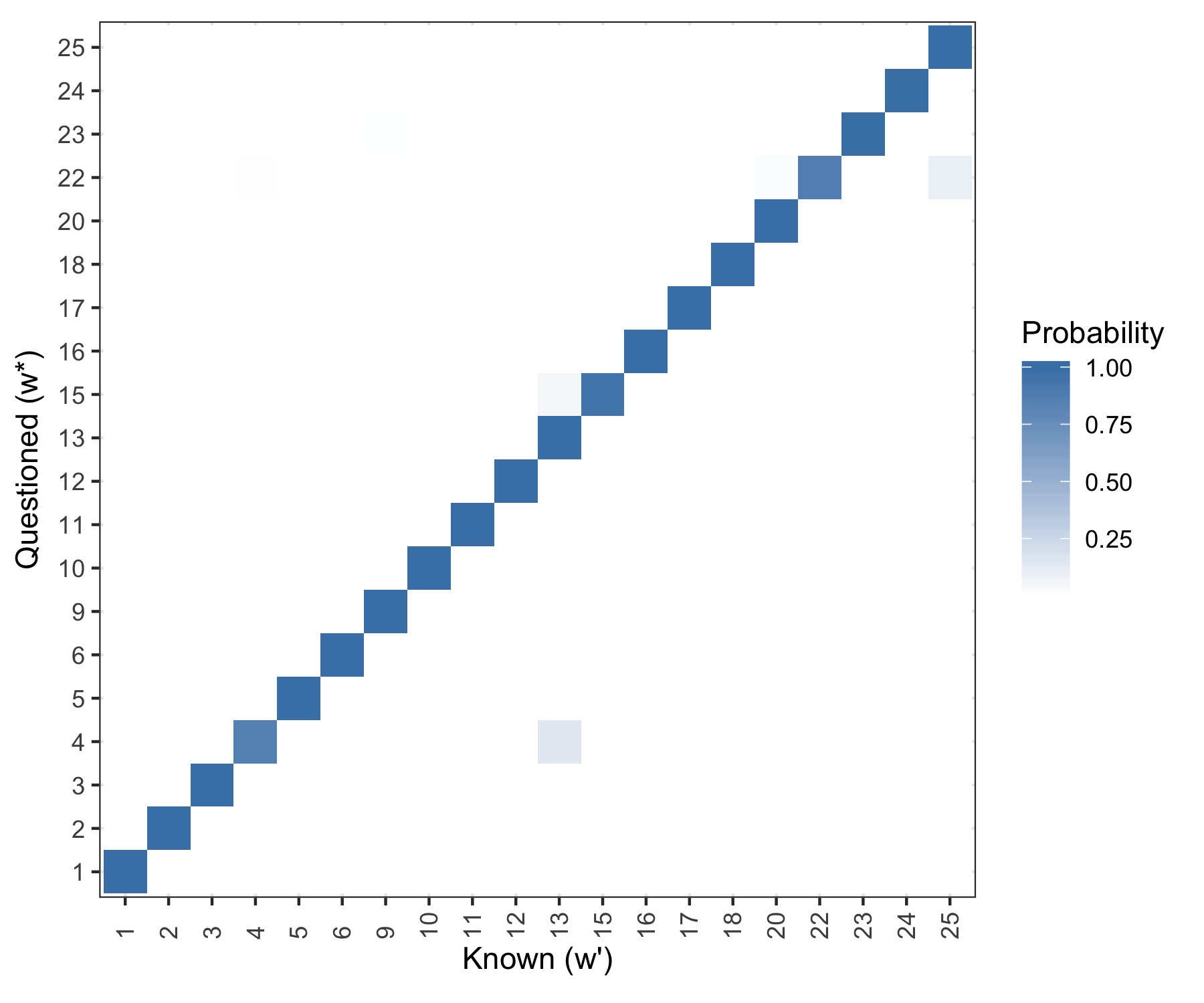
Figure 5.31: Posterior predictive results. Rows are evaluated independently and the probability in each row sums to one.
Not surprising. Working on:
- More writers (need to go through handwriter)
- Testing on the phrase prompt
- Including not yet seen CVL writers in analysis.
Model #3, Normal Slopes. Work in progress.
Adding slope measurements into the model.
Let,
\(\boldsymbol{Y}_{w(d)} = \{Y_{w(d),1}, \dots, Y_{w(d),K}\}\) be the number of glyphs assigned to each group for document within writer, \(w(d),\)
\(\boldsymbol{\bar{S}}_{w(d)} = \{\bar{S}_{w(d),1}, \dots, \bar{S}_{w(d),K}\}\), be the average slope in each group for document \(w(d)\)
- \(G_{w(d),j}\) be the \(j^{th}\) glyph in document \(w(d)\),
- \(g_{w(d), j} = 1, \dots, 41\) be the available cluster assignments for the \(j^{th}\) glyph in the document,
- \(S_{w(d),j}\) be the slope of the \(j^{th}\) glyph in the document.
Here, \(K = 41\), \(d = 1,2,...,5\), \(w = 1,...,27\), \(j= 1, \dots,\mathrm{J}_{w(d)}.\)
\[ \bar{S}_{w(d),k}= \frac{1}{Y_{w(d),k}} \sum_{j \ni \mathrm{I}[g_j = k]}S_{w(d),j} \quad \& \quad Y_{w(d),k} = \sum_{j = 1}^{\mathrm{J}_{w(d)}} \mathrm{I}[g_j = k] \]
Then a hierarchical model for the data is
\[\begin{array}{rl} \mathbf{Y}_{w(d)} | \boldsymbol\pi_{w}, w\: &\stackrel{ind}{\sim} \:Multinomial(\boldsymbol\pi_{w}), \\ \boldsymbol{\pi}_w|\boldsymbol{\alpha} \:&\stackrel{ind}{\sim}\:Dirichlet(\boldsymbol{\alpha}), \\ \alpha_k\: &\stackrel{iid}{\sim}\: Gamma(a = 2, \: b= 0.25), \\ \bar{S}_{w(d),k} | Y_{w(d),k}, w, \mu_{w, k}, \sigma^2_{k} \: & \stackrel{iid}{\sim}\: N \left(\mu_{w, k}, \frac{\sigma^2_{k}}{Y_{w(d),k}}\right) \\ \mu_{w, k} | \mu_{k} \: & \stackrel{iid}{\sim}\: N(\mu_{k}, 3) \\ \mu_{k} \: & \stackrel{iid}{\sim}\: N(0, 3) \\ 1/\sigma^2_{k}\: & \stackrel{iid}{\sim}\: Gamma(0.5, 0.1) \end{array}\]
Consider a new document with cluster fill counts \(\boldsymbol{Y}^*\) and average slope measurements \(\boldsymbol{\bar{S}}^*\) from unknown writer \(w^*\).
Posterior Predictive Analysis
Posterior probability that the questioned document belongs to writer \(w^\prime\) with respect to the closed set is:
\[\begin{array}{rl} &p(w^* = w^\prime|\boldsymbol{\bar{S}}^* \boldsymbol{Y}^*, \dots) \nonumber \\ &\qquad \qquad \propto \left[ \: \prod_{k=1}^{K}p(\bar{S}^*_k | Y^*_{k}, w^* = w^\prime, \dots) \right] p(\boldsymbol{Y}^* | w^* = w^\prime, \dots ) \nonumber \\ &\qquad \qquad \approx \frac{1}{M} \sum_{m=1}^{M} \left[ \: \prod_{k=1}^{K}N \left(\mu_{w, k}^{(m)}, \frac{\sigma^{2(m)}_{k}}{Y_{w(d),k}}\right) \right] Mult(\boldsymbol{Y}^*; \boldsymbol{\pi}_{w^\prime}^{(m)}) \nonumber \end{array}\]for MCMC samples \(m = 1, \dots, M\).
Results
Evaluate the posterior probability of writership for each of the holdout documents.
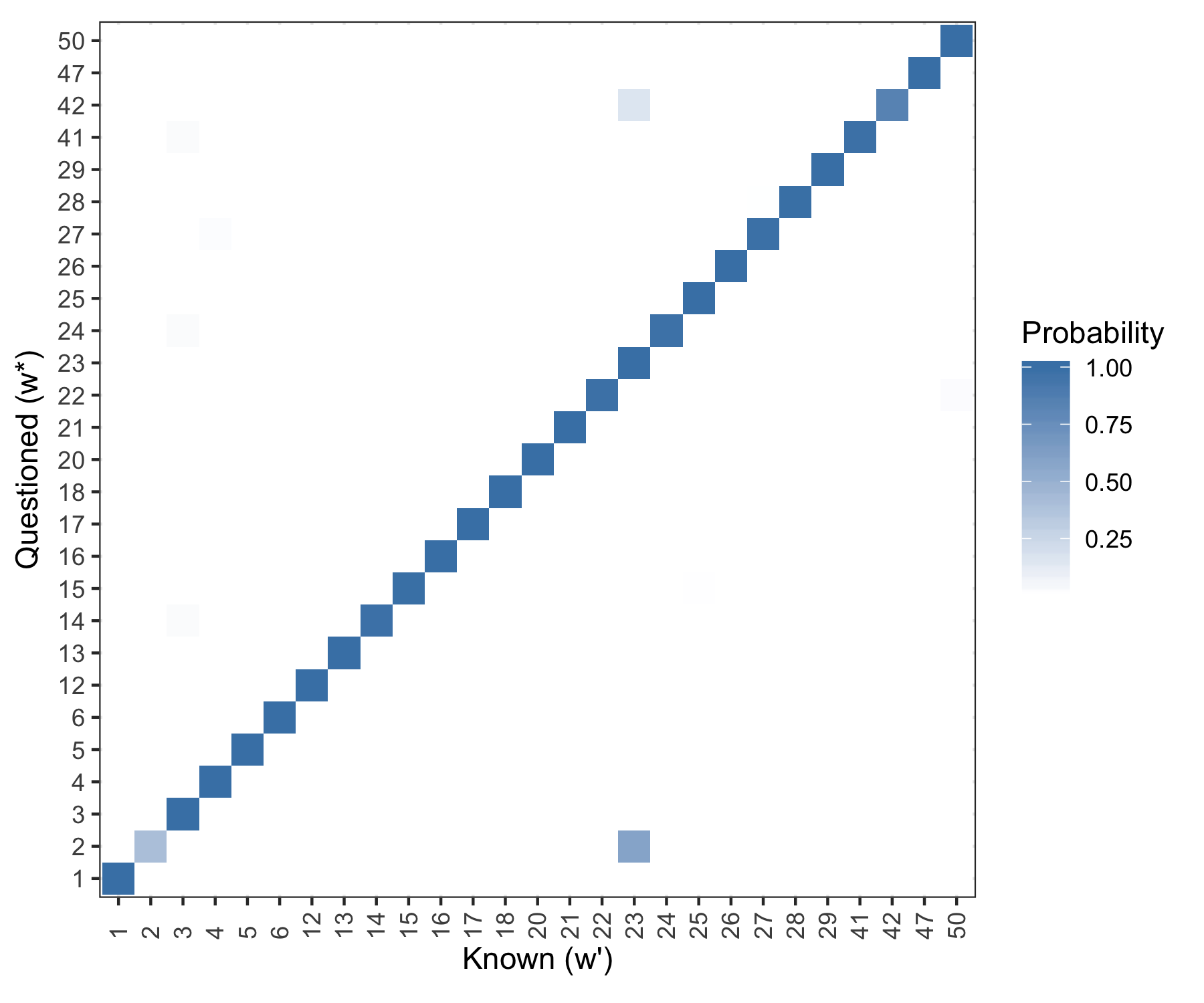
Figure 5.32: Posterior predictive results. Rows are evaluated independently and the probability in each row sums to one. Log Loss = 0.0883.
Modeling Summary
| Model | Data | LogLoss |
|---|---|---|
| #1 | Adjacency Grouping (not presented) | 0.5413 |
| #1 | Cluster Grouping | 0.2013 |
| #2 | Cluster Grouping | 0.2078 |
| #3 | Cluster Grouping & Glyph Slopes | 0.0883 |
5.3.2.2 Modeling update (Feb 17)
90 writers, Session #1
Train: 3 London Letters
- A few writers only had 2 (working on this)
Test: 1 Wizard of Oz
Recall rotation angle measurements:
Figure 5.33: Data: All Cluster #29 graphs in Writer 95’s training documents. Left: A Nightingale Rose diagram displaying the rotation angles in 20 ‘petals’. A point for each observed rotation angle is plotted on the outermost ring of the diagram. Right: A traditional histogram of the rotation angles with 20 bins, a point for each observation is plotted on the x-axis.
A NAIVE Model for Rotation Angles
Naively we can treat the rotation angle values as if they are linear on the interval (0,\(\pi\)). This is of course not the case, since a value of 0 is extremely similar to a value of \(\pi\), both corresponding to letters that do not lean a great deal to the left or right, and are wider than they are tall. This can be seen in Figure 2, where the unimodal density ends abuptly at zero and “wraps around” in the higher values near \(\pi\). Nonetheless, we can specify a disribution on the linear, or unwrapped, rotation angles as follows: \[\begin{align} \nonumber \mathbf{Y}_{w(d)} | \boldsymbol\pi_{w}, w \: &\stackrel{ind}{\sim} \:Multinomial(\boldsymbol\pi_{w}), \\ \nonumber \boldsymbol{\pi}_w|\boldsymbol{\gamma} \: &\stackrel{ind}{\sim}\:Dirichlet(\boldsymbol{\gamma}), \\ \nonumber \gamma_k\: &\stackrel{iid}{\sim}\: Gamma(a = 2, \: b= 0.25), \\ \nonumber & \quad \\ \nonumber SRA_{w,k} | w,k \: & \stackrel{iid}{\sim}\: Beta \left( \alpha_{w,k}, \beta_{w,k} \right) \\ \nonumber & \quad \\ \nonumber \mu_{w,k} &= \frac{\alpha_{w,k}}{\alpha_{w,k}+\beta_{w,k}} \: \sim Beta(2,2) \\ \nonumber variance_{w,k} &= \frac{\mu_{w,k}(1 - \mu_{w,k})}{\alpha_{w,k} + \beta_{w,k} + 1} = \frac{\mu_{w,k}(1 - \mu_{w,k})}{\kappa_{w,k}+1} \\ \nonumber \kappa_{w,k} &= \alpha_{w,k} + \beta_{w,k} \: \sim Gamma(shape = 0.1, rate = 1) \end{align}\]
Where \(SRA_{w,k,i}, \: \:i = 1, \dots, n_{w,k}\), are rotation angles from cluster \(k\), and writer \(w\), scaled to the beta density support of (0,1). For a given writer and cluster, \(\mu_{w,k}\) is the mean of the data distribution, expressed as a functions of \(\alpha_{w,k}\) and \(\beta_{w,k}\). We place a weak prior, \(Beta(2,2)\), on all \(\mu_{w,k}\). Similarly, \(\kappa_{w,k}\) is expressed as a function of \(\alpha_{w,k}\) and \(\beta_{w,k}\) and is a sort of “sample size”, or “precision” parameter. Notice that \(\kappa_{w,k}+1\propto\frac{1}{variance_{w,k}}\).
Figure 5.34: Writer 95, Cluster 29. A plot depicting elements of the data model \(SRA_{w,k} \: \sim \: Beta ( \alpha_{w,k}, \beta_{w,k})\). Top: values of \(\alpha^{(m)}_{95,29}\) and \(\beta^{(m)}_{95,29}\) for \(m = 1, \dots,12\) iterations taken from the middle of the chain and used to plot the \(12\) correpsonding beta densities. Bottom: the unscaled rotation angles (unscaled \(SRA_{w,k}\)), serving as data for the parameter estimation.
For a different writer who does not tend to lean one way or another…
Figure 5.35: Nightingale rose diagrams and traditional histograms for the rotation angles from Writer #1’s training documents in Clusters #29 (top) and #16 (bottom).
And we can look at a handful of beta distributions that arise from \(w=1\) and \(k=16\)…
Figure 5.36: Writer 1, Cluster 16. A plot depicting elements of the data model \(SRA_{w,k} \: \sim \: Beta ( \alpha_{w,k}, \beta_{w,k})\). Top: values of \(\alpha^{(m)}_{1,16}\) and \(\beta^{(m)}_{1,16}\) for \(m = 1, \dots,12\) iterations taken from the middle of the chain and used to plot the \(12\) correpsonding beta densities. Bottom: the unscaled rotation angles (unscaled \(SRA_{w,k}\)), serving as data for the parameter estimation.
Why am I showing you histograms and MCMC samples from clusters #29 and #16?? Becasue these are great examples of where the problems occur with the naive approach to modeling the “unwrapped” angles.


Figure 5.37: Cluster members in grey, and cluster exemplars in red (plotting is a few pixels shifted left) for clusters \(\#29\) (left), and \(\#26\) (right)
These are clusters that tend to hold the letters \(n\) and \(u\) and thus, are generally wider than they are tall. When a writer emits one of these nearly straight up and down, but slightly right leaning, the rotation angle will be just above zero. If the graph is very slightly left leaning, then the rotation angle will be just under \(\pi\).
While the beta distribution can take on a \(U\)-shape (like the Writer 1, Cluster 16 data in Figure 4), this is still undesirable, becuase we want to express the fact that values near \(0\) and \(\pi\) are actually very similar. For example, a mean near \(\pi/2\) does not do a good job of expressing the center of those rotation angles, and a traditional “unwrapped” variance will overstate the variability in data that is actually quite similar.
Consider the following distribution of cluster #16 rotation angles from writer #85’s questioned document. The largest observation is 3.129, which scales to 0.996, the next largest is 3.024, which scales to 0.963. These are going to accumulate a huge amount of likelihood when evaluated under the beta parameters for Writer #1, displayed in Figure 6. The rest of the rotation angles are relatively spread out over the \(x\)-axis, and not necessarily reflective of the Writer #1 distribution in Cluster #16.
Figure 5.38: Questioned Document. Writer #85. Cluster #16.
QD evaluation under beta distributed rotation angles using \(k=1,\dots,20\), the \(20\) most populated clusters. Notice the probability for questioned writer #85 that is assigned to known writer #1. This error is explained by the behavior depicted above. Not all off-diagonal probability assignment can be attributed to similar behavior, but much of it can.
Figure 5.39: Posterior predictive evaluation of QDs under beta distributed rotation angles.
A Wrapped Model for Rotation Angles
A more appropriate approach to the problem is to consider the rotation angles in the polar coordinate system and treat them as spanning the full circle. So we map the upper half plane values to \((0,2\pi)\), where values above the \(x-\)axis indicate a right leaning graph and below the \(x-\)axis indicate left leaning graphs. Graphs that are relatively straight up and down will have values near \(0/2\pi\) if they are wider than they are tall, and near \(\pi\) if they are taller than they are wide.
Figure 5.40: Writer 1, Cluster 16. Left: linear consideration of the rotation angles. Right: wrapped rotation angles on the full circle.
Figure 5.41: Two candidate distributions defined on circular data, both specified at MLE parameter values calculated from the data.
We consider two distributions that are appropriate for circular data. First, the von Mises distribution is a close approximation to the wrapped normal distribution, which is the circular analouge of the normal. This is the “go-to” unimodal wrapped distribution, like the normal is the traditional “go-to” unimodal distribution. It is specified through the mean, \(\mu\), and concentration, \(\kappa\) (\(\frac{1}{\kappa}\) analogous to \(\sigma^2\)).
The second is the wrapped Cauchy distribution, which is the wrapped version of the Caucy distribution. Similar to the traditional Cauchy, this distribution is symmetric, unimodel, and specified by a location parameter, \(\mu\), and concentration parameter, \(\rho\). This distribution is also heavy-tailed in the sense that it will place more density on the “back” of the circle opposite the peak of the distribution.
Now, consider \[\begin{align} \nonumber \mathbf{Y}_{w(d)} | \boldsymbol\pi_{w}, w \: &\stackrel{ind}{\sim} \:Multinomial(\boldsymbol\pi_{w}), \\ \nonumber \boldsymbol{\pi}_w|\boldsymbol{\gamma} \: &\stackrel{ind}{\sim}\:Dirichlet(\boldsymbol{\gamma}), \\ \nonumber \gamma_k\: &\stackrel{iid}{\sim}\: Gamma(a = 2, \: b= 0.25), \\ \nonumber & \quad \\ \nonumber RA_{w,k} | w,k \: & \stackrel{iid}{\sim}\: Wrapped \: Cauchy \left( \mu_{w,k}, \phi_{w,k} \right) \\ \nonumber \mu_{w,k} &\sim Uniform(0,2\pi) \\ \nonumber \phi{w,k} &\sim Uniform(0,1) \\ \nonumber \end{align}\]
Where \(RA_{w,k,i}, \: \:i = 1, \dots, n_{w,k}\), are rotation angles from cluster \(k\), and writer \(w\), on the full circle \((0,2\pi)\). For a given writer and cluster, \(\mu_{w,k}\) and \(\phi_{w,k}\) are the location and concentration parameters, respectively. We place non-informative uniform priors on each. Again, there is no borrowing set up in the model for rotation angles. Each writer/cluster combination gets its own estimated rotation angle distribution.
QD evaluation under wrapped Cauchy distributed rotation angles, using \(k=1,\dots,20\), the \(20\) most populated clusters. Notice the probability for questioned writer #85 that was previously assigned to known writer #1 is no longer an issue.
Figure 5.42: Posterior predictive evaluation of QDs under wrapped Cauchy distributed rotation angles.
5.3.3 Interesting documents
5.3.3.1 Where do we miss?
We tend to do worse on writers who only had 2 training documents.

Writers 32 and 133.
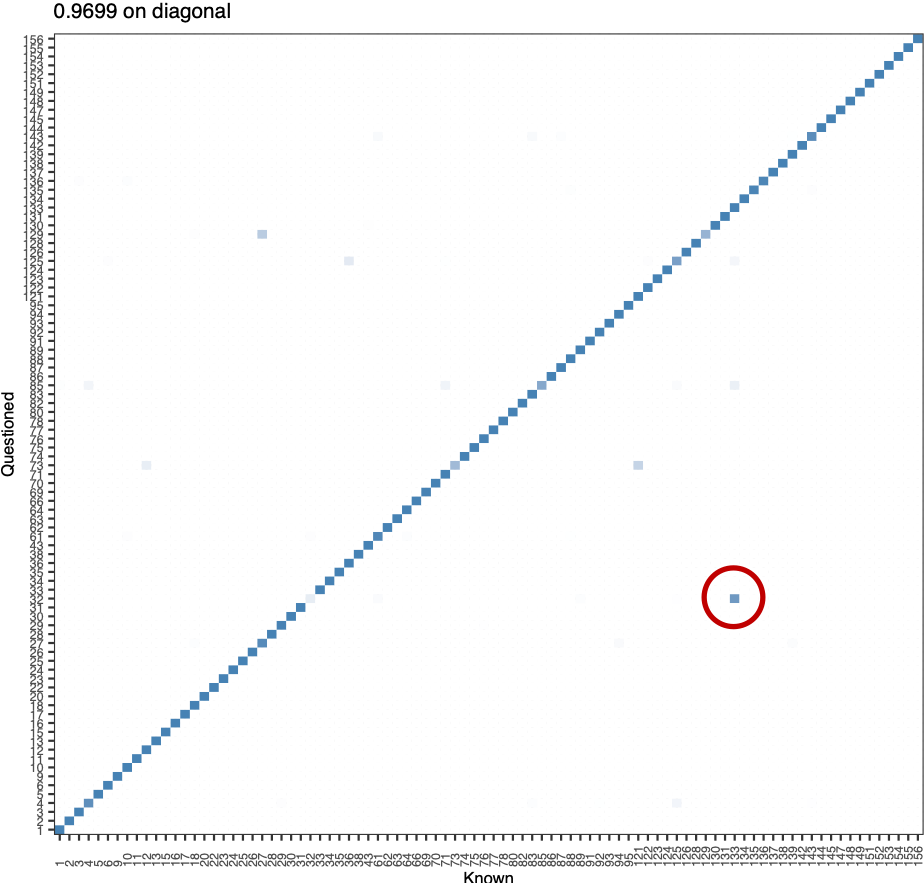
Figure 5.43: All 40 documents, wrapped cauchy rotation angles, where do we miss?
Samples:
Writer 32 Test

Figure 5.44: Writer 32 Test
Writer 133 Train

Figure 5.45: Writer 133 Train



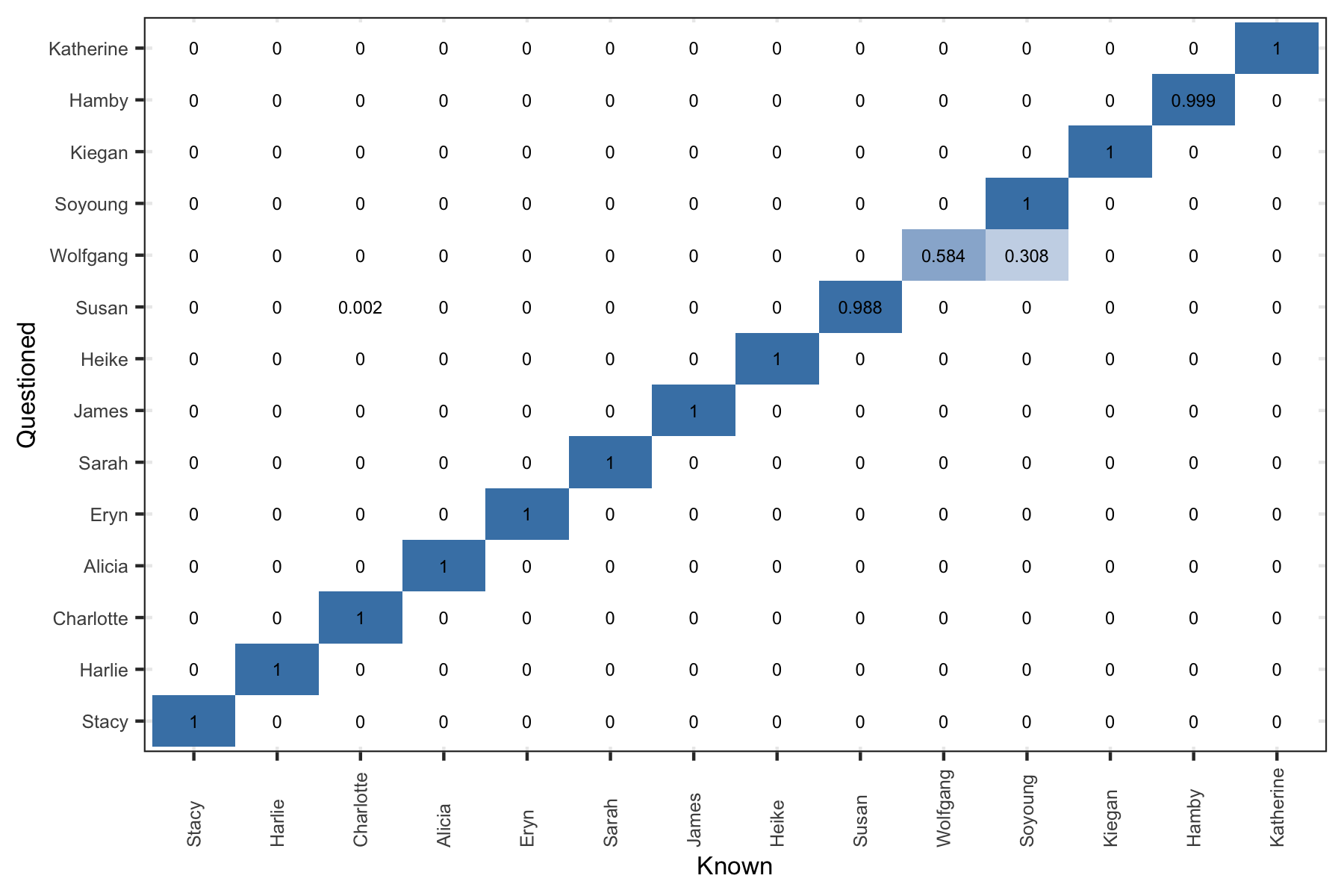



5.3.5 Open Set Modeling for Writer Identification from Distribution of Glyphs in Clusters
The next step in this research extends the scope of potential sources of handwriting samples to an open set. So if there are two handwriting samples, are what is the probability they are from the same writer or different writer without the neccesary assumption of knowing all of the potential sources. The distribution of glyphs assigned to clusters in a document is can be used to explore the authorship because it is hypothesized that a particular writer would have their own writing style resulting in similar distributions of glyphs in each cluster over time across many different writing samples.
Instead of comparing multinomial distributions, the proportions of total glyphs in each cluster can be compared with two Dirichlet distributions. If there are two different samples where the length of the documents differ the expected number of glyphs per cluster would also differ. For example, if samples of handwriting were found at two different scenes and the goal is to compare the two documents, it would be expected that the number of glyphs in each cluster would vary unless they happened to write the exact same thing in both. Dirichlet distributions would compare the proportions instead of the counts of glyphs per cluster.
To start we will look at a dirichlet with three proportions, which would correspond to only having three clusters, and calculate the euclidean distance.
KDE (kernel density estimation) can be used to estimate the behavior of the distributions when the random variables are indeed from the distribution with the same parameters and when they are drawn from the distribution with different parameters.
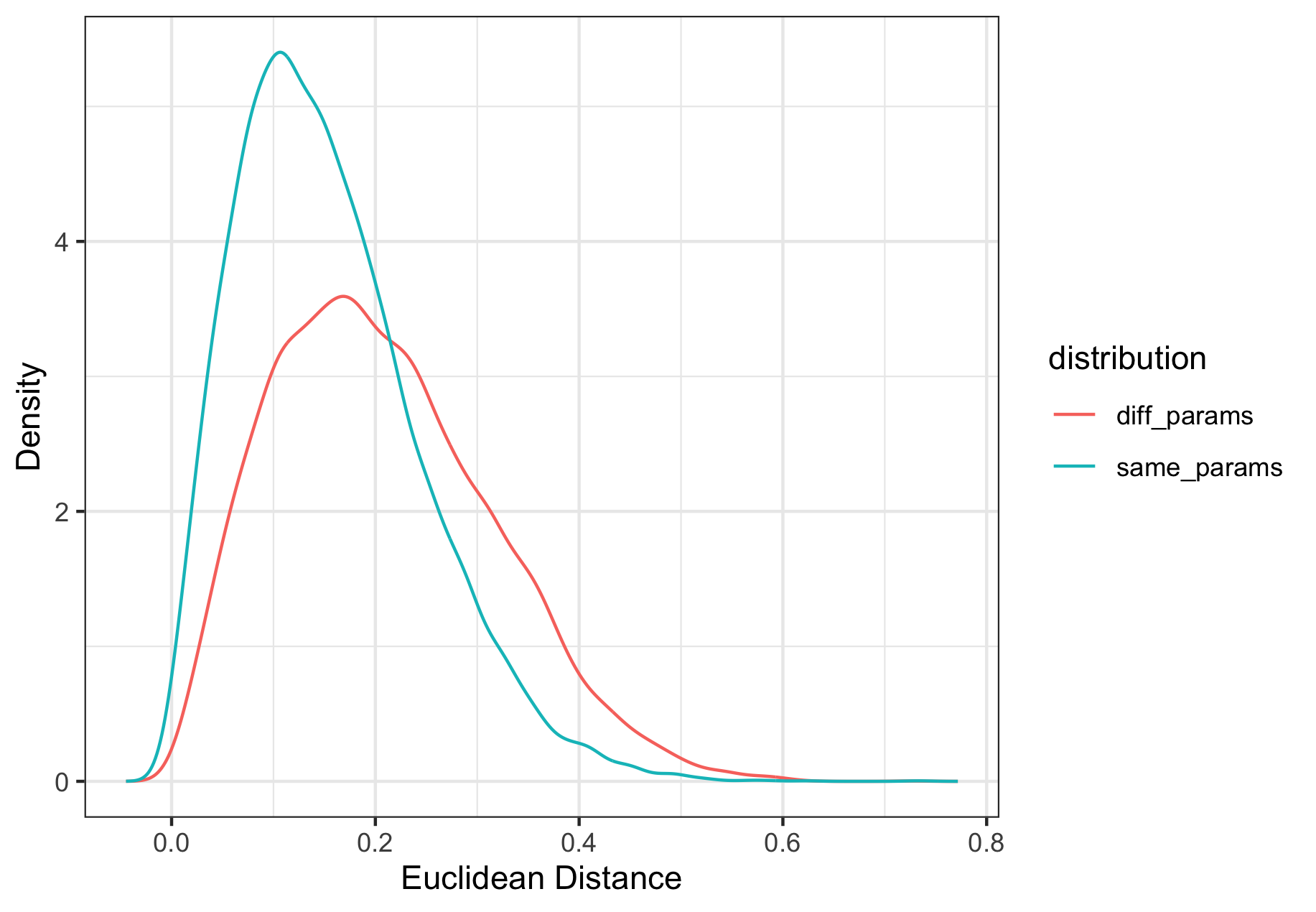
These density estimates can be used to calculate score-based likelihood ratios (SLRs) using leave-one-out of another simulated dataset. We would expect SLRs that are greater than 1 to be associated with the distance measures from the same distribution.
This process was conducted with just the euclidean distance to start. Next, it is possible to assess how well a random forest with multiple distance measures (euclidean distance and the absolute difference between each of the clusters) can correctly identify if two dirichlet random variables are from a distribution with the same parameters or different parameters.
To do this, 10,000 random variables were simulated for two dirichlet with the parameters (5,10,25) and one dirichlet with parameters (6,12,22) as a training set. The distance measures were calculated between the two dirichlet from the same parameters and also between different parameters. These distance measures were added to a dataset along with an indicator if the distance measures were from the same or different dirichlet.
Next, a random forest was trained to predict the if the distance measures were from the same or different dirichlet.
A testing dataset was simulated in the same way as before and the random forest was applied. The random forest returns a value between 0 and 1 which is the proportion of trees in the forest that predicts the distance measures are from the same dirichlet.
The training dataset was split into those that were actually from the
same and different parameters. The stat::density() uses kernel density
estimation with a Gaussian kernel to estimate the probability density
function of the proportions that predicted the dirichlet were simulated
from the distrution with the same parameters after defining the range of
the pdf to be between 0 and 1.
Using the leave-one-out method, 1 observation was excluded from the dataset and then KDE was performed.
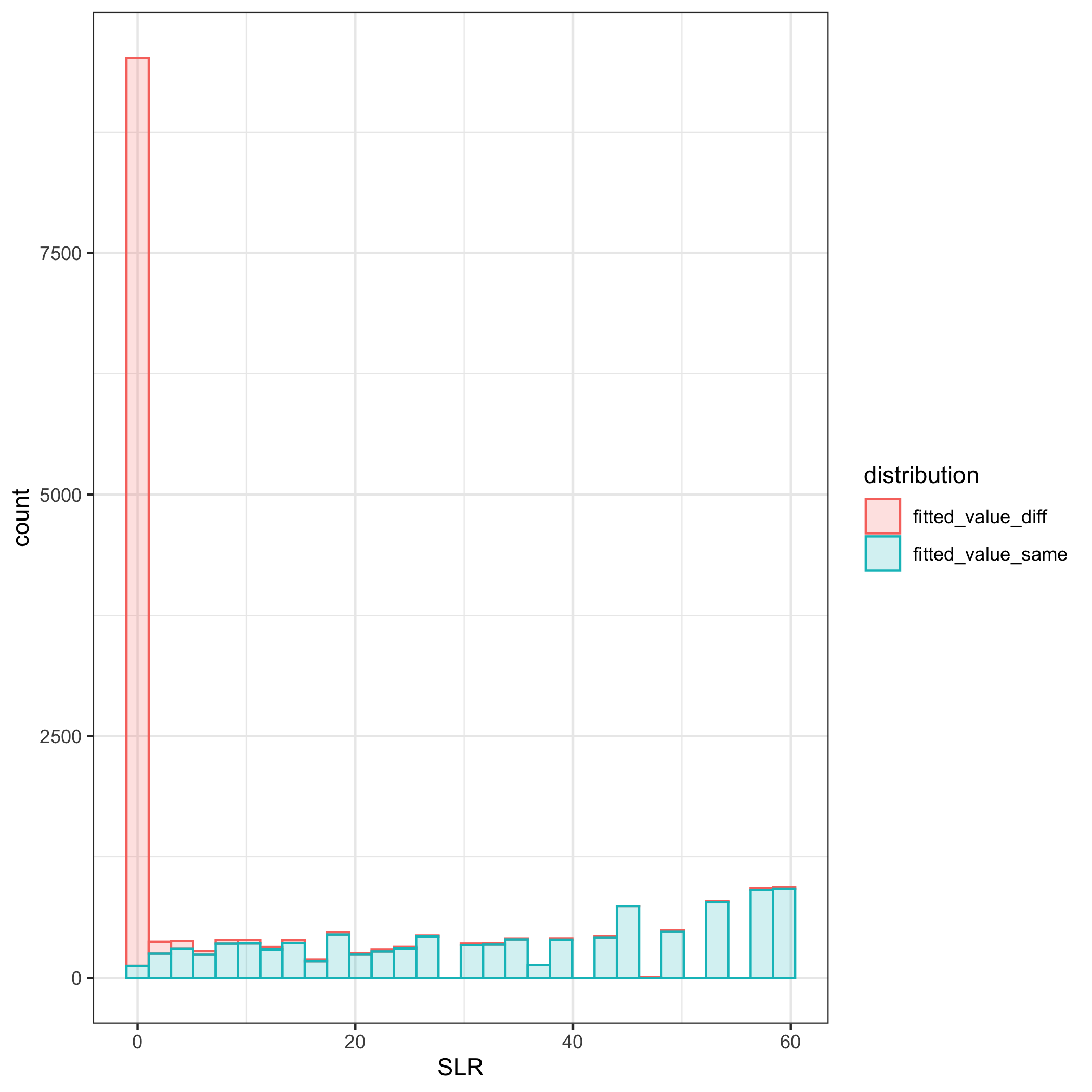
The ratio of the KDE estimate for the curve if the excluded point was from the distribution with the same parameters to different parameters is computed. The SLRs are compared for those that are actually from the same vs different and we would expect there to be little overlap.

The same process that was conducted with 3 clusters was repeated with 40 clusters. A random forest was trained on simulated data with 40 clusters with randomly simulated parameters drawn from a uniform distribution. There appears to be little overlap between the kernel density estimates that were drawn from the same distribution compared to those from different distributions.
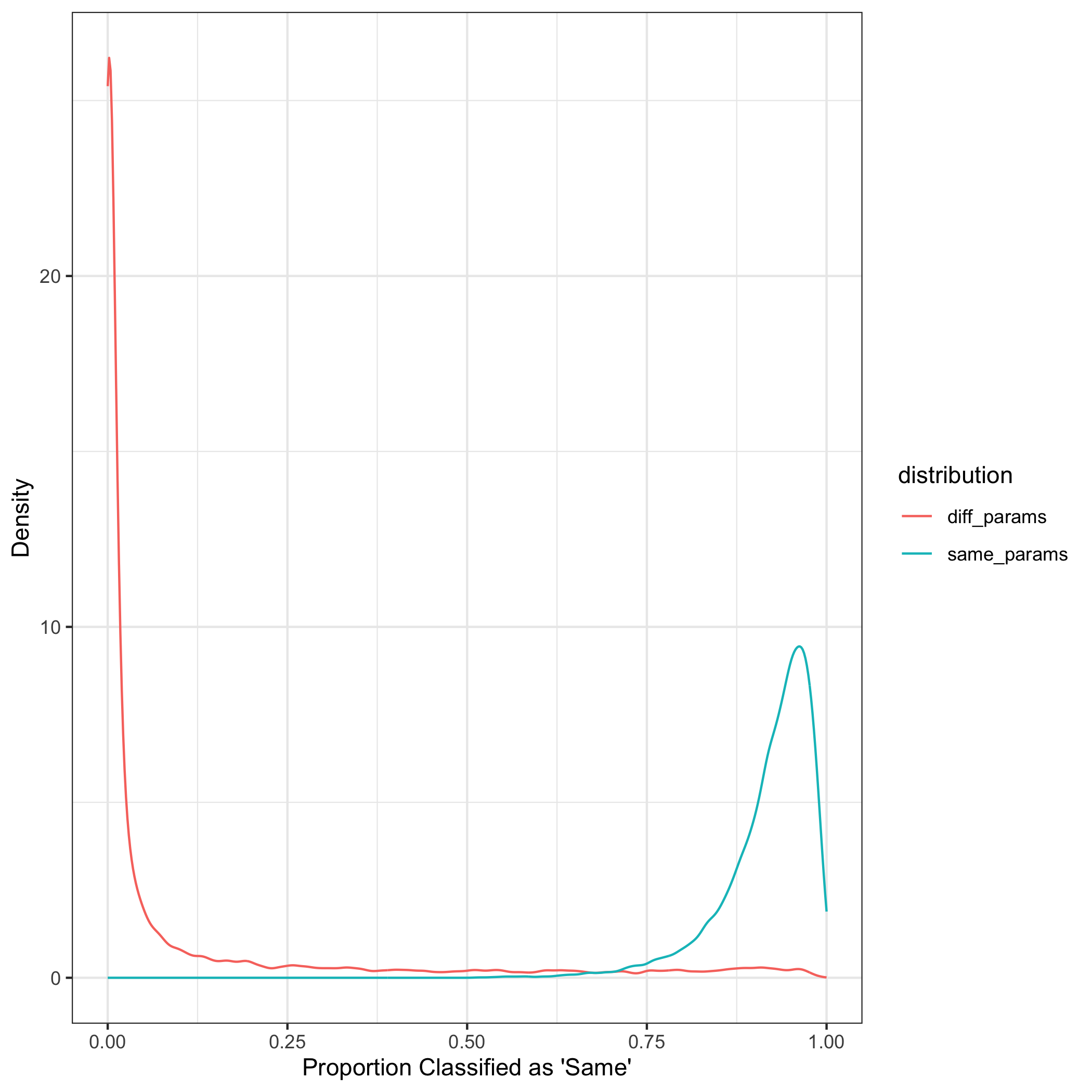
While the small SLRs are based on the distance measures from dirichlet with different parameters and larger SLRs are from the same as expected, the score likelihood ratios computed using the leave-one-out method are not as distinct of those from the same compared to different dirichlet distributions as we would expect.

Application to CSAFE Database
The data provided in the CSAFE database consist of writing samples from 90 writers who repeated three prompts three times throughout three sessions for a total of 9 writing samples per writer. The three prompts varied in length. “The London Letter” is the longest and has been used in other handwriting analyses because it includes all of the letters upper and lowercase and numbers. The second is an excerpt from “The Wizard of Oz” book. The last prompt is the short phrase: “The early bird may get the worm, but the second mouse gets the cheese”(Crawford, et al.). This initial test on the data only includes the documents from the first session.
We repeated the process of evaluating the score-based likelihoods calculated from the kernel density estimates of the output a random forest previsouly applied to simulated data to the CSAFE handwriting data. We used 4 different prompts: London Letter, Wizard of Oz, short phrase, and all prompts per writer per repetition combined. The combined document is longer and would be expected to be more representative of the writing style of each writer in the study.
For each data set, a random sample of 80% of the writers was drawn. The distance measures between all pairs of documents were calculated (absolute difference between each glyph and euchlidean distance) from sample. The number of distances from the same source were counted and the same number of different source distances were down sampled. This created a training set that includes an equal number of distances between same and different sources to train the random forest. The resulting random forest was trained using the remaining 20% of the writers not initially sampled for the training data set. As before with the simulated data, distributions of the output from the random forest by source was estimated using kernel density estimation with a Gaussian kernel with bounds between 0 and 1. SLRs were computed using the leave-one-out method as before.
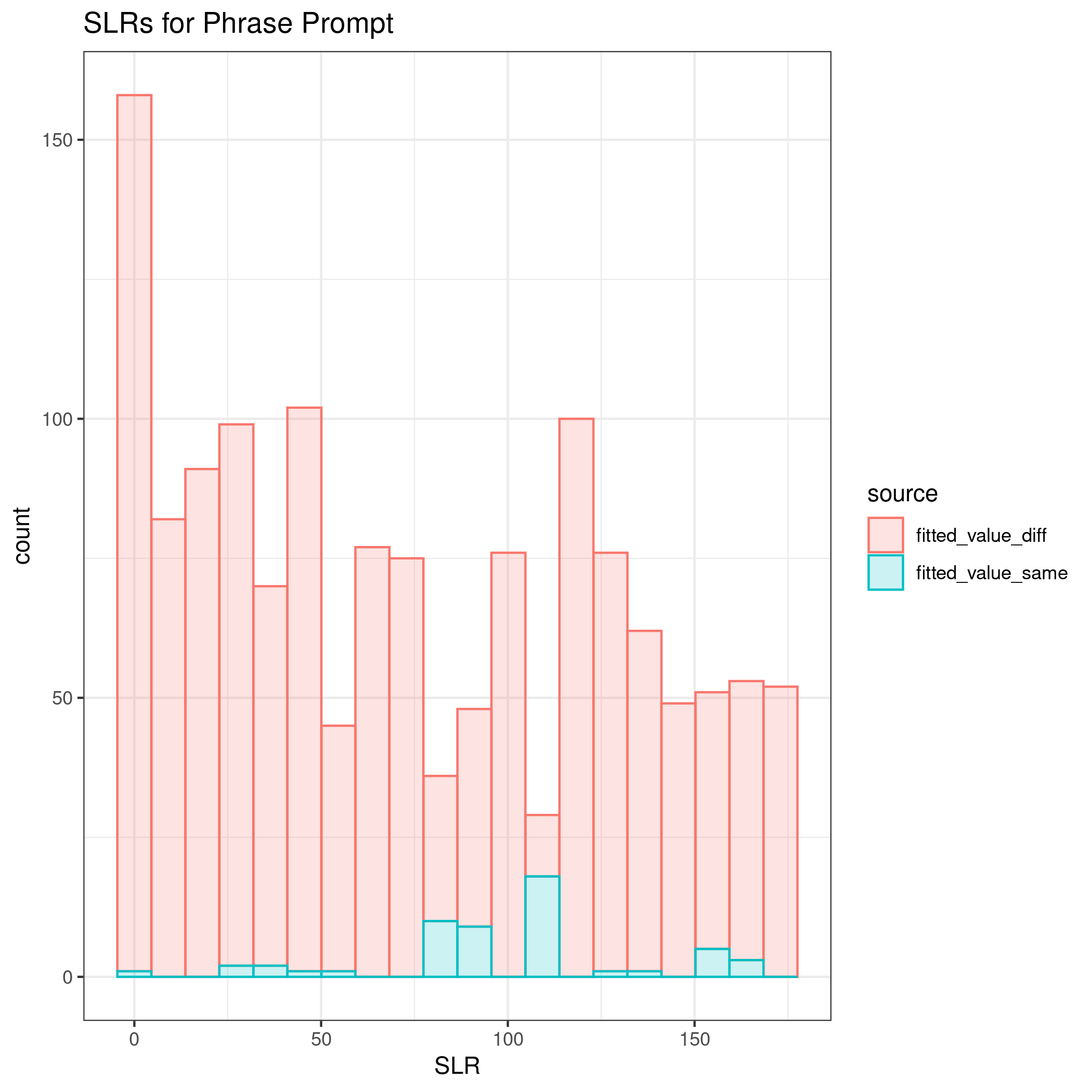
The first prompt is the short phrase.


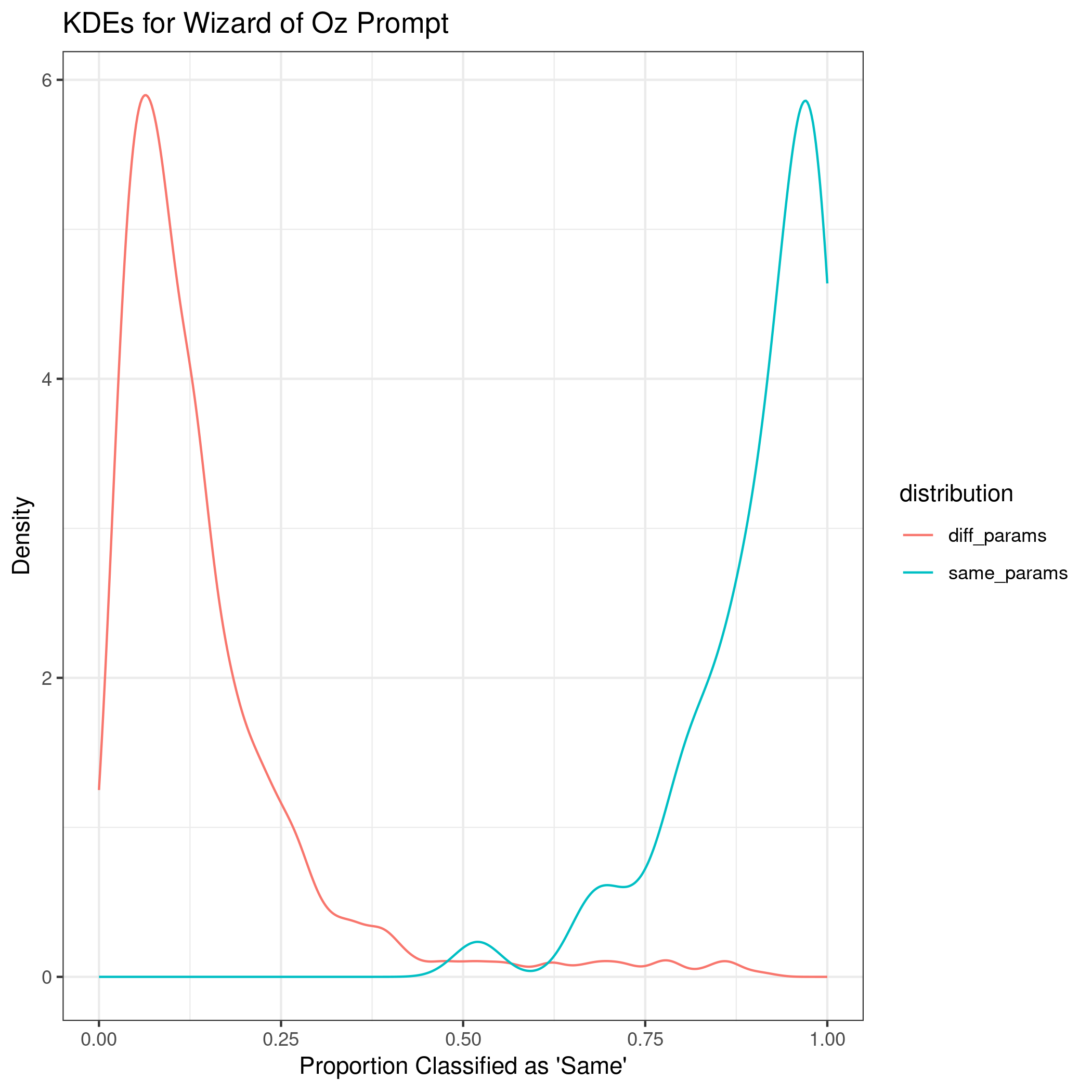
The next prompt is an excerpt from “The Wizard of Oz”.


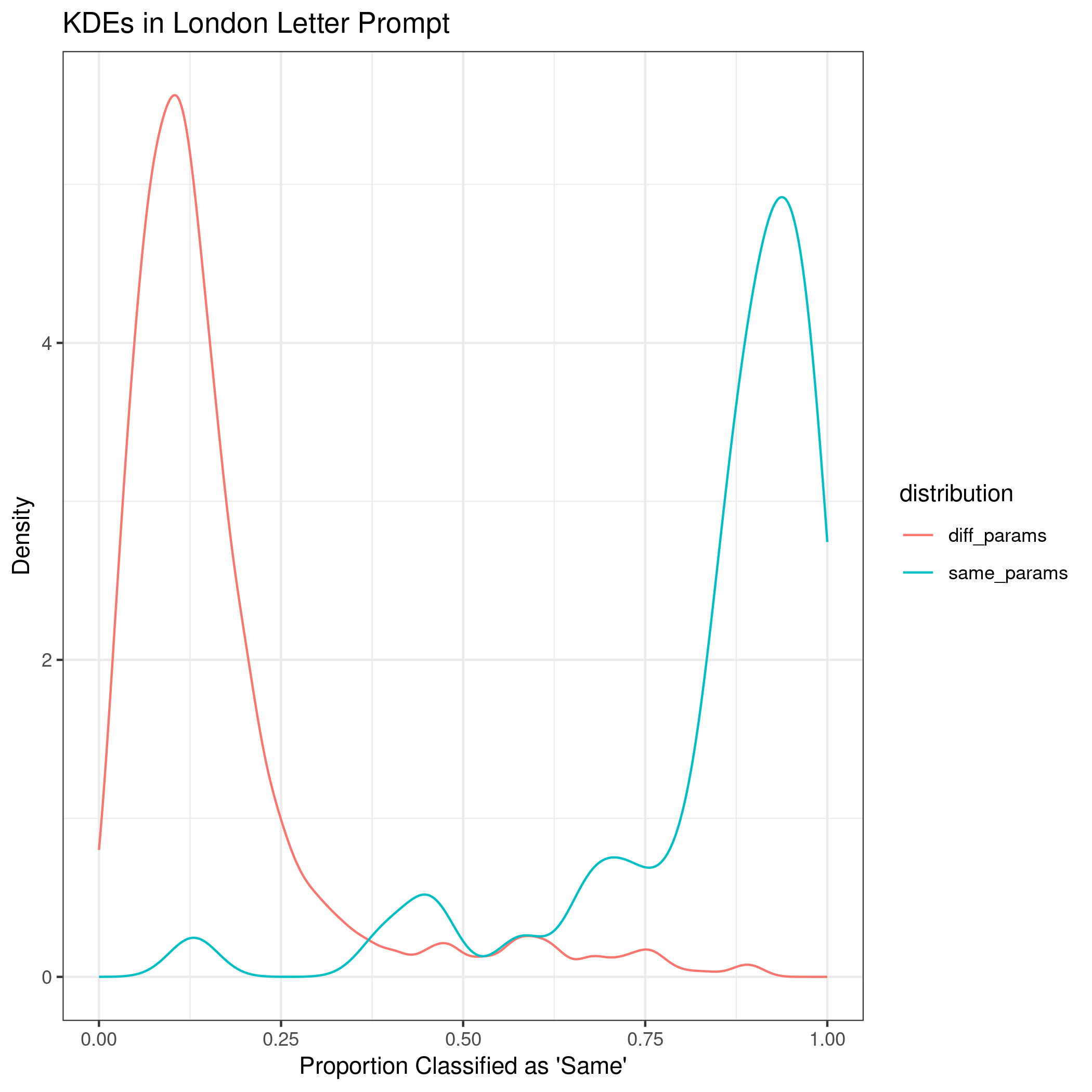
The third prompt is the “London Letter”.

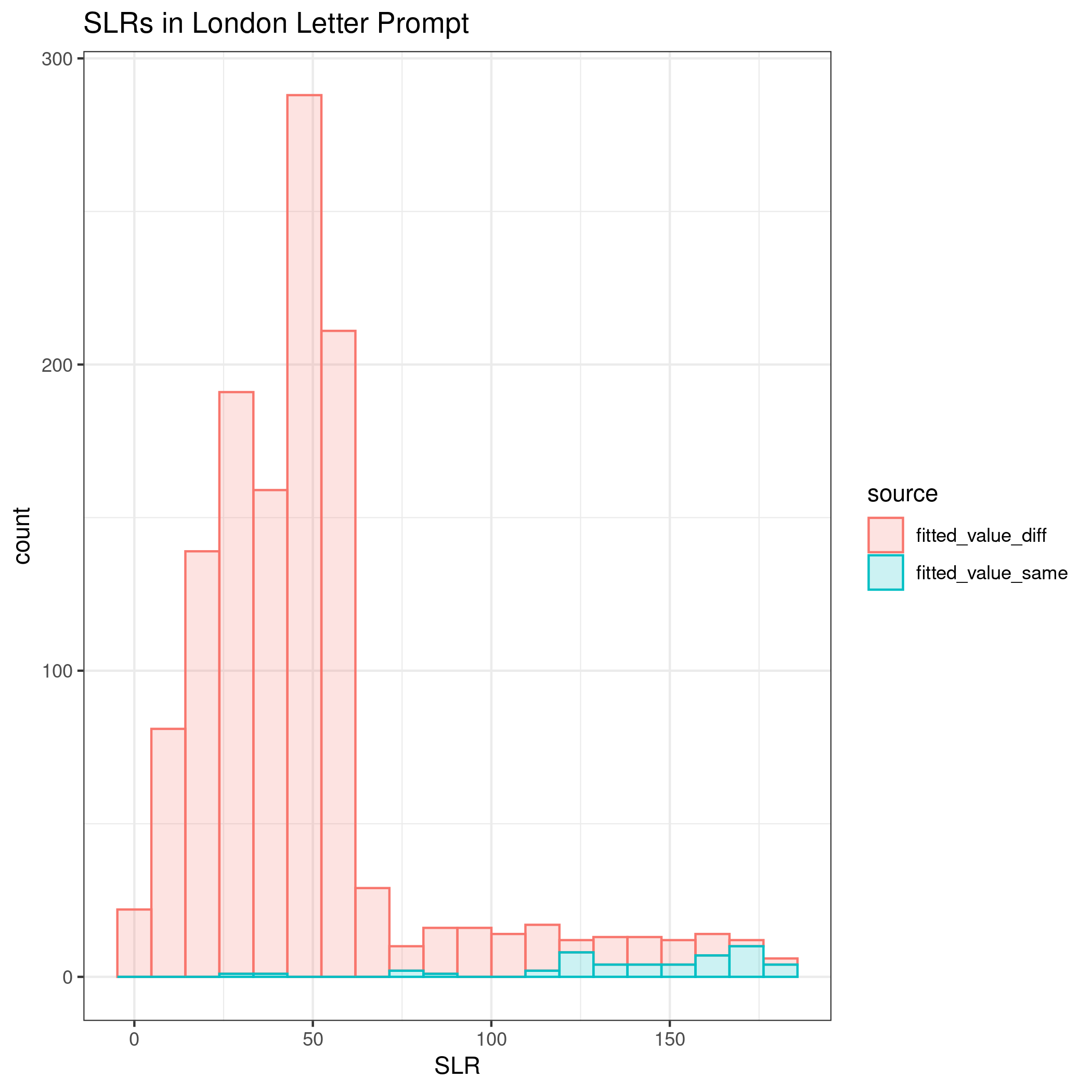
Lastly, all three documents are combined into one large template per writer.
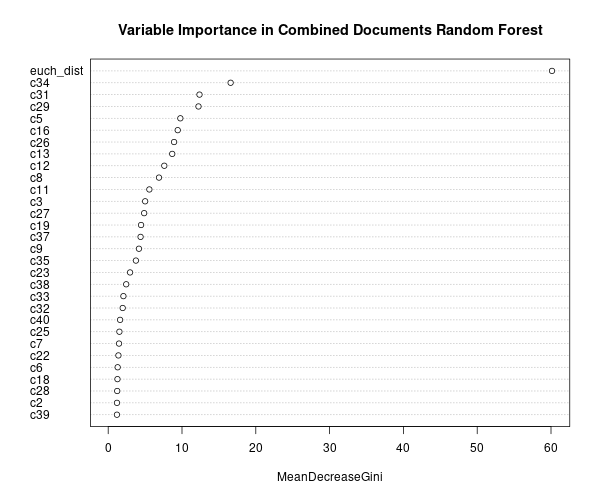


Comparing all four implementations of the process, the method did the best at correctly classifying same vs. different source with longer documents. The euclidean distance was the most important variable according to the mean decrease in Gini index. Additionally, when comparing the absolute difference by cluster, some clusters appear to be more influential across prompts, such as cluster 31.
The kernel density estimates for the shortest prompt are not well separated. As the length of the writing sample increases, the KDEs between same and different sources become more distinct.
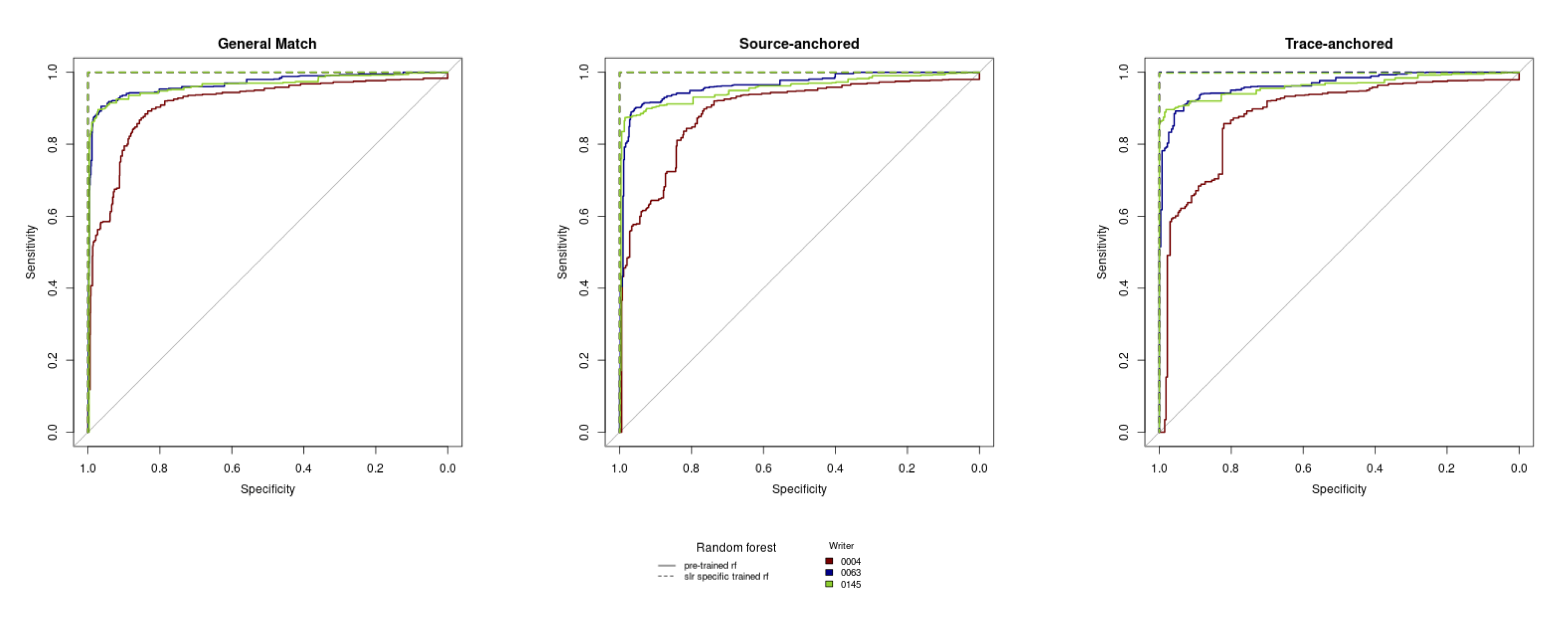
The discrimination of source using SLRs can be quantified using AUC by prompt as 0.6447, 0.7293, 0.9692, and 0.961 for the short phrase, Wizard of Oz, London Letter, and all prompts combined, respectively.

Tippett plots are an additional way to visualize the behavior of the SLRs under the prosecution and defense hypotheses.
## Error in knitr::include_graphics(c("images/handwriting/mattie/tippett.png")): Cannot find the file(s): "images/handwriting/mattie/tippett.png"It is important to note that the training set did down sample the number of different source differences, but the testing set did not so the number of SLRs in that are from different sources will be more than from the same (a pattern not seen in the simulated data).
Hepler et al detail score-based likelihood ratios by specific source instead of common (but unknown) source. The three specific source SLRs are general match, source anchored, and trace anchored. To compare the behavior of each with the CSAFE handwriting database, we extracted 3 writers (“sources”) by ordering the all of the Euclidean distances, ordering the sum of distances by each writer, selecting the smallest, middle, and largest value.
The numerator value is constructed by combining all documents written by each writer to create a “template”. This template is randomly split into 2 “pseudo-documents” 1000 times. The distance measures are calculated between each pair and used in the trained random forest to find dissimilarity scores.
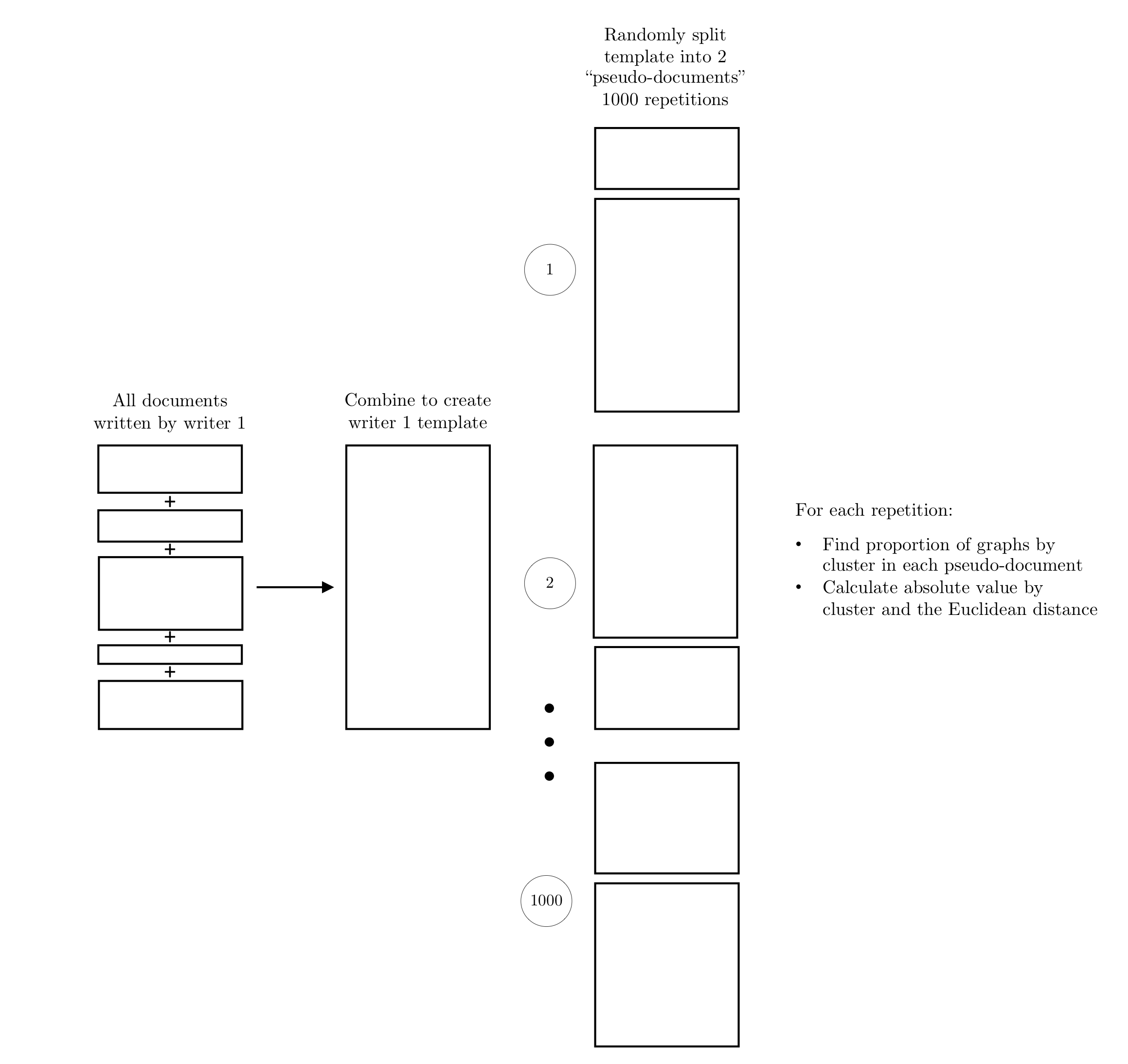
The three SLRs denominators are defined by which documents are compared.
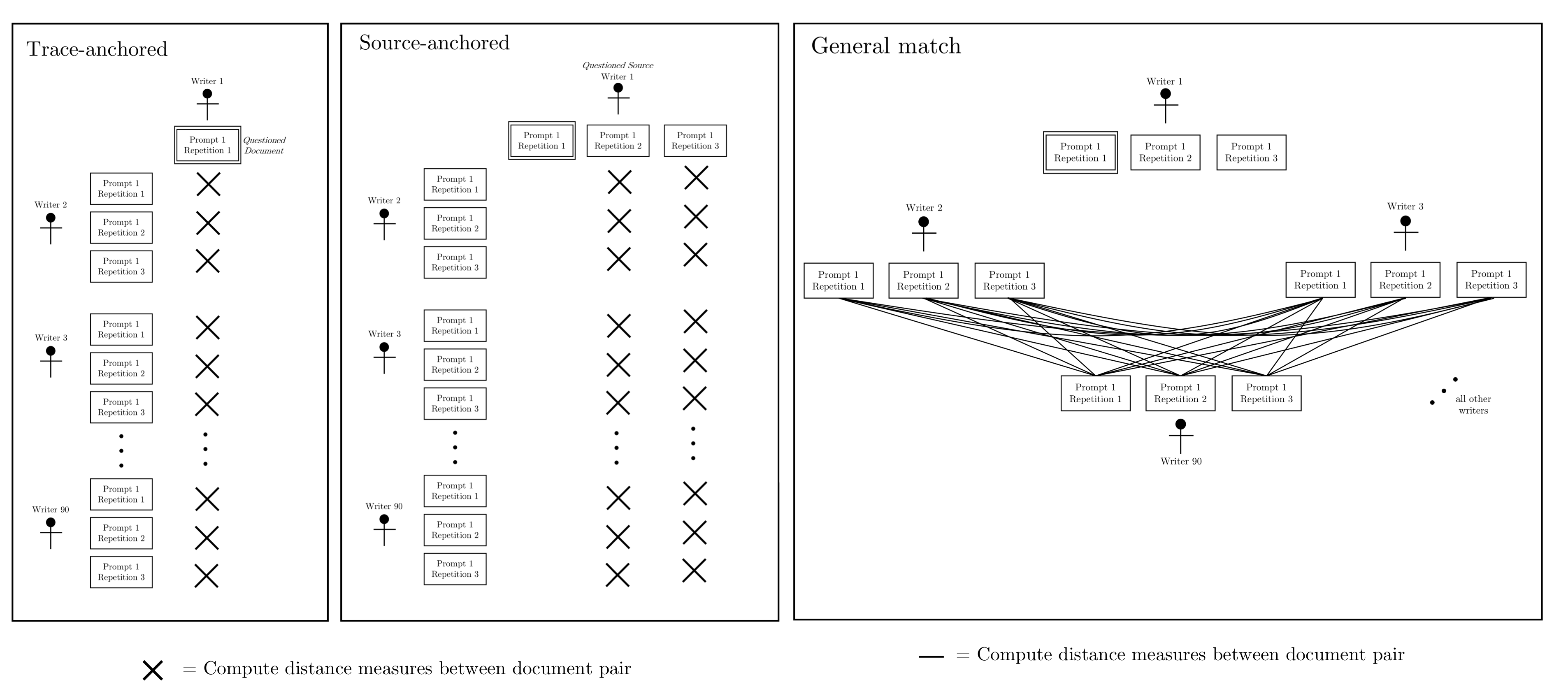

The discrimination of the three SLRs across the three selected writers within the CSAFE database can be visually compared across the three selected writers with ROC curves. There are two different random forests implemented to find the SLRs. The “pre-trained” random forest is the same random forest used with the common source SLRs, while the SLR specific trained SLRs are trained on a subset of the distance measures used to compute each of the three specific source SLRs.

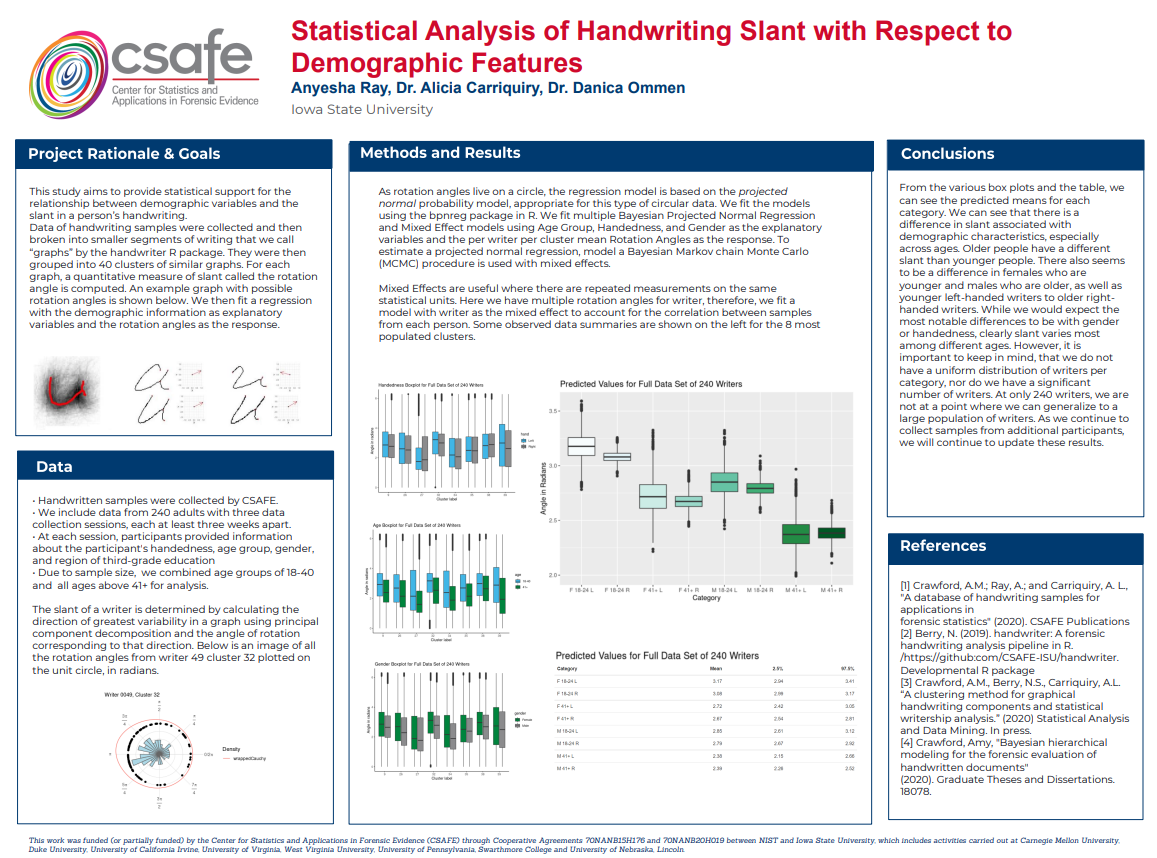
5.3.6 Statistical Analysis of Handwriting Slant with Respect to Demographic Features
5.3.6.1 Background
This study aims to use statistical analysis to determine if there is a relationship between demographic features and slant. Generally, it is believed that there is a relationship between demographic features such as gender and age of a person and their handwriting.
5.3.6.2 Methods and Data
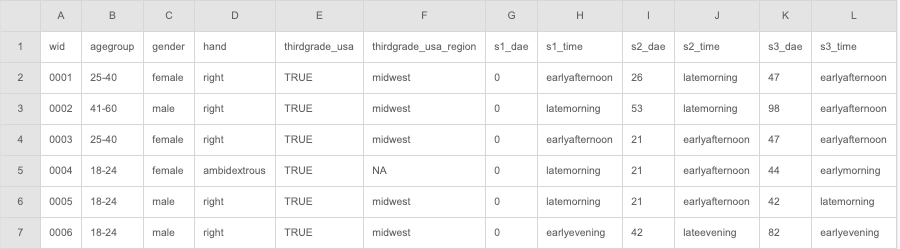
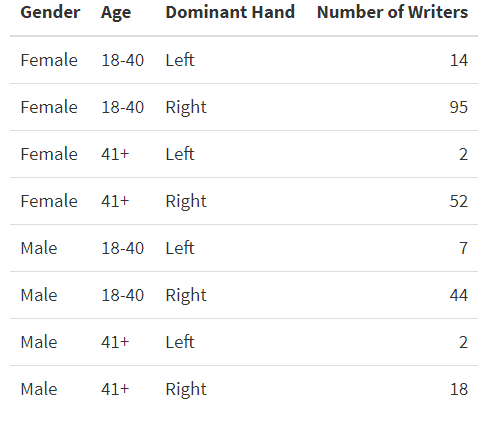
Data Handwritten samples were collected by the Center for Statistics and Applications in Forensic Evidence (CSAFE). We include data from 235 adults. Each participant completed three data collection sessions at least three weeks apart. Participants wrote three different prompts that have three different lengths: the London Letter being the longest, followed by an excerpt chosen from the book The Wonderful Wizard of Oz, and the phrase “The early bird may get the worm, but the second mouse gets the cheese.” At each session, participants transcribed the three writing prompts three times resulting in nine pages of samples. In total, each writer wrote twenty-seven pages over the course of the study. Currently, we have about 6345 handwriting sample images as well as demographic-specific information collected from surveys for all participants.
Participants also provided information about their handedness, age group, gender, and region of third-grade education. Due to sample size, we did not include region in the models, and we combined age groups to 18-40 and 41+.
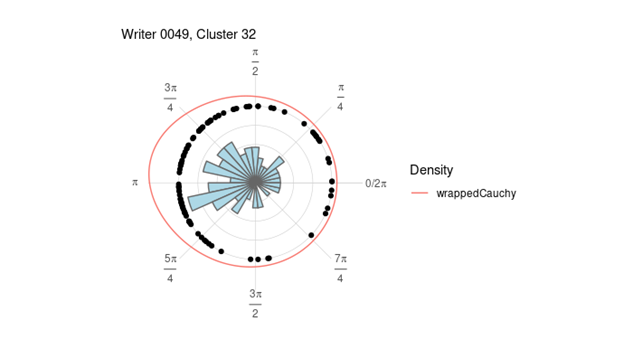
All handwriting images are broken into smaller segments of writing that we call “graphs” by the handwriter R package [2][3]. We extract information such as curvature of the glyph, lengths, and heights, as well as shapes of the loops. Following the methods described in Crawford [4], these graphs are then grouped according to their basic shape into 40 different clusters. For each glyph in a cluster, a quantitative measure of slant is computed. The slant of a writer is determined by calculating the direction of greatest variability in a letter using principal component decomposition and the angle of rotation corresponding to that direction. We call this the rotation angle of a glyph, which is a numerical value between 0 and 2π. The rotation angle is the measure of slant we use in our modeling. Since each graph has a measurement of slant, we have over 500,000 observations. To simplify this, we average all the rotation angles to get per person per cluster measurements. In other words, we take each writer and average the rotation angles that are in the same cluster. This gives us a data frame of approximately 10000 observations since each writer can only have, at most, 40 clusters. This also accounts for the issue of the different number of rotations angles a writer could have. Below is an image of all the rotation angles from writer 49 cluster 32 plotted on the unit circle, in radians.
To get the data into a usable form, we did have to do some cleaning and manipulation. The data in its raw form is images with QR codes and information about the participant, like writer id and session information. We first crop out that information, and then extract all the features. Then, we are left with data files for each individual writer per session. The data files contain lists of 9 for each document in that session. Inside the list is information such as the name of the file, the image, and any data we could use for analysis sorted by letter. We extract the information relevant to my analysis and merge it with the file containing all the survey information.
Since we have multiple options for the 4 categories of interest, we have many possible combinations of writers. However, we do not have enough participants to fill all the categories, especially region. Due to this we look at region separately, but do not include it in our final model. We collapse the age categories to be between 18-40 and 41+ instead of having 4 groups. We also have two writers that are ambidextrous but do not include their data in the model as we do not have enough information for those writers.
5.3.6.3 Model
Our model is based on circular regression instead of linear regression. Circular data is information measured on the unit circle in radians or degrees. For example, linear data may consist of varying heights, while anything related to measurements of angles or something periodic in nature such as time would be considered circular data. For our purposes, we use circular regression instead of linear regression.
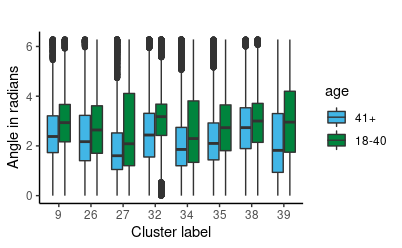
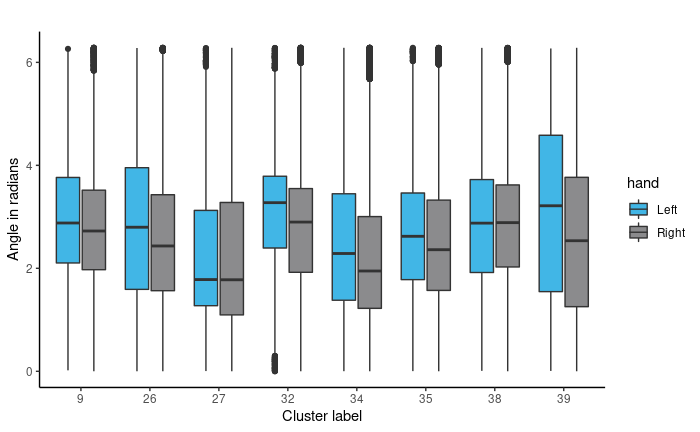
Once we have established the use of circular regression, we must fit an appropriate model. We chose to use Bayesian circular regression. Models considered were Bayesian fixed effects models and mixed effects. As we have nested variables (multiple clusters and rotation angles within writers), we chose to fit a Bayesian mixed effects model. Mixed Effects are useful where there are repeated measurements on the same statistical units. Here we coded writer as the random effect to account for the correlation between samples from each person, since rotation angles from the same person are more likely to be similar than rotation angles from different people. Some observed data summaries are shown to the for angles in the 8 most populated clusters of graphs.
We also averaged the rotation angels per writer per cluster. The original data is set up to have a rotation angle for each graph. Therefore, we have multiple rotation angles per document, and more when we factor in all 27 pages of documents. Since we have thousands of angle measurements, we average them per writer per cluster, where we take each person, organize by clusters and average the rotation angles that have the same cluster assignment. This way, each person has at most 40 observations since the number of clusters per person does not exceed 40. Some observed data summaries are shown for angles in the 8 most populated clusters of graphs.
## Error in knitr::include_graphics(c("images/handwriting/anyesha/rotangexample.png")): Cannot find the file(s): "images/handwriting/anyesha/rotangexample.png"
We fit the models using the bpnreg package in R. We fit multiple Bayesian Projected Normal Regression and Mixed Effect models using Age Group, Handedness, and Gender as the explanatory variables and the per writer per cluster mean Rotation Angles as the response. The MCMC algorithm has 5000 iterations with 2000 burn-in. We only show results for the model that includes a random effect for person.
5.3.6.3.1 Regression
## Error in knitr::include_graphics(c("images/handwriting/anyesha/model_writeup1.png")): Cannot find the file(s): "images/handwriting/anyesha/model_writeup1.png"## Error in knitr::include_graphics(c("images/handwriting/anyesha/model_writeup2.png")): Cannot find the file(s): "images/handwriting/anyesha/model_writeup2.png"5.3.6.4 Conclusion
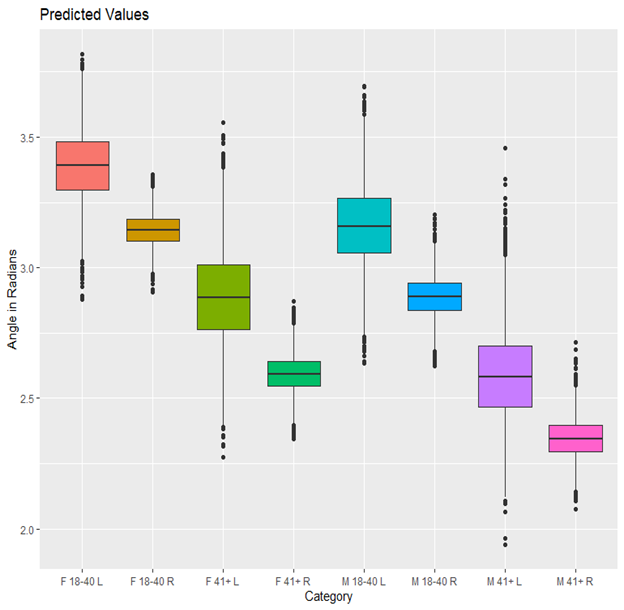
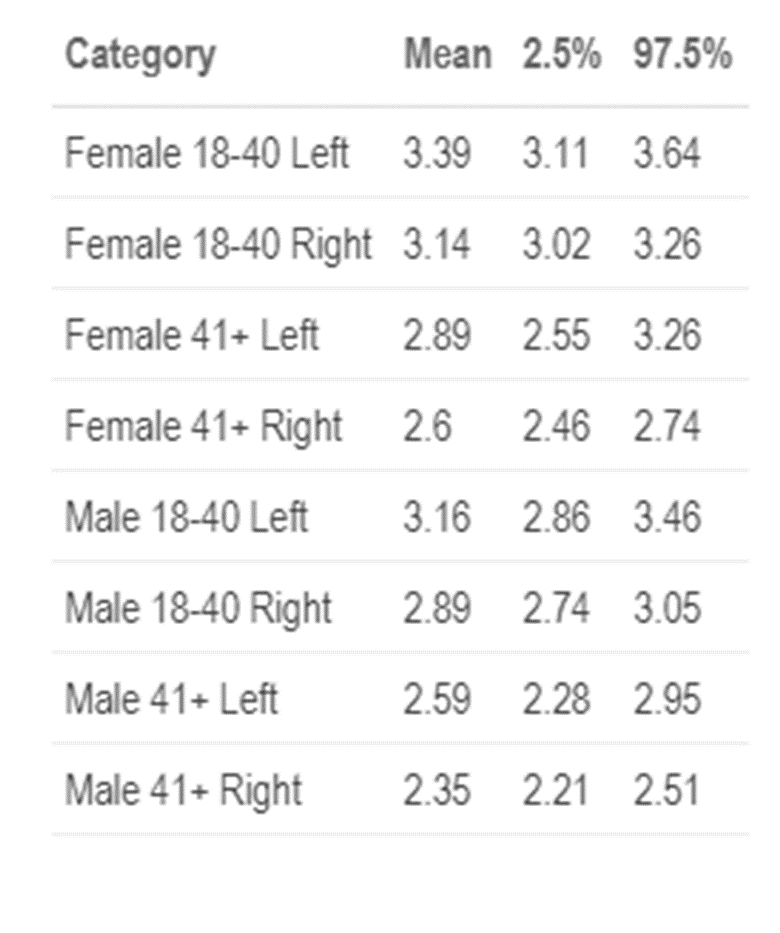
In the boxplot and from the above table, we can see the predicted means for each category. We can see that there is a difference in slant associated with demographic characteristics especially across ages. Older people have less of a slant than younger people . There also seems to be a difference in females who are younger and males who are older, as well as younger left-handed writers to older right-handed writers. While we would expect the most notable differences to be with gender or handedness, clearly slant varies most among different ages. However, it is important to keep in mind, we do not have a uniform distribution of writers per category, nor do we have a significant number of writers. We will continue to collect samples from additional participants and will update these results when more data becomes available.
5.3.7 Quantifying Bayes Factors for Forensic Handwriting Evidence
5.3.7.1 Background
Amy’s work developed a closed set model for handwriting identification. Closed set means we have a finite background population, and that the model can identify which writer wrote which sample given we know that each writer wrote a sample in the set. From here we want to move to identify handwriting samples in an open set. Here we do not know the background population and are simply looking to answer did the suspected writer write this sample or not. Mattie approached this issue using score-based likelihood ratios and Gab did it using Neyman-Pearson Likelihood Ratios and Bayes Factors. In the score based likelihood approach they combined features into a score metric and then compared those where as in the NP-LR method/BF method we compare the features directly. My work will continue what Gab did and run multiple simulations to support her proof-of-concept study.
Diff b/w LR and BF: Gab calculated both the NP-LR and BF. Likelihood ratios are accepted in the forensic community which is why I’m guessing we use them. Law of Likelihood: “If Hypothesis A implies the probability that X = x is \(p_A(x)\), while Hypothesis B implies the probability that X = x is \(p_B(x)\), then the observation X = x is evidence supporting Hypothesis A over Hypothesis B if and only if \(p_A(x)\) > \(p_B(x)\) and the Likelihood Ratio \(p_A(x)\)/\(p_B(x)\) measures the strength of that support.” In the forensic lens, this means probability of observing the evidence given prosecution (matches suspect) is true, divided by probability of observing the evidence given defense (match is from a randomly selected someone in the relevant population i.e., not the suspect). This is based on the MLE. A Bayes Factor is the Bayesian version of a LR. Probability of observing evidence under one hypothesis to probability of observing data under the other. They are interpreted in the same way. If the ratio is greater than 1 it supports the prosecutions and ratios below 1 support the defense.
The CSAFE data is broken down using handwriter. Writing samples are broken into glyphs, and each glyph is categorized into a cluster group based on their basic shapes (simplified example is that all things that look kind of like an e will go into the same cluster). We do 40 clusters because Amy said so. Then Gab created a dataset that has the cluster counts for each writer (writer 1 has 2 graphs in cluster 1, 16 in cluster 2, and so on to 3 graphs in cluster 40 then same for writer 2 and so on…).
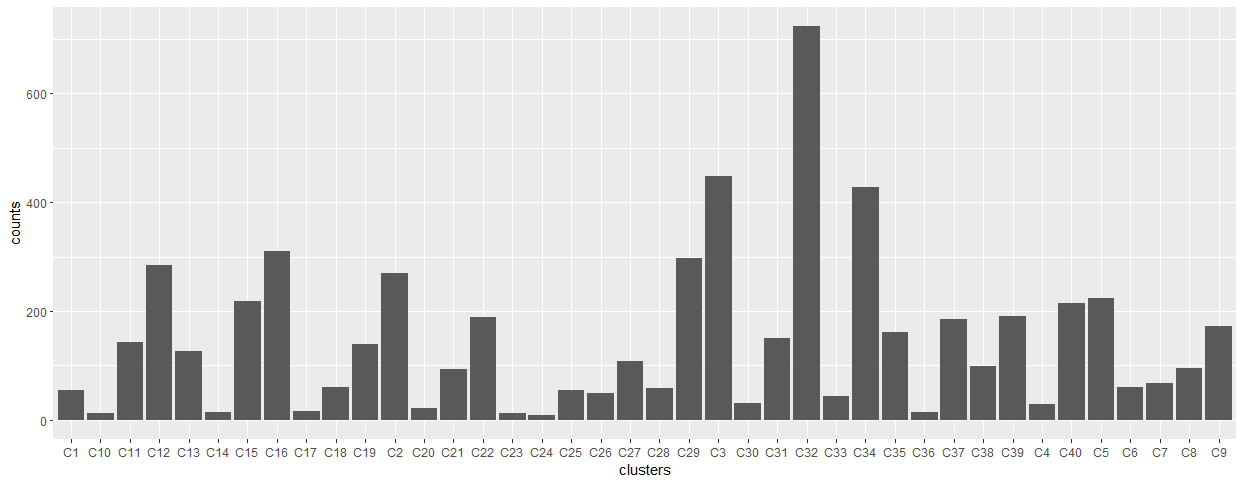
Figure 5.53: Figure 1. Histogram of graph count sums across all pieces of writing from writer 1
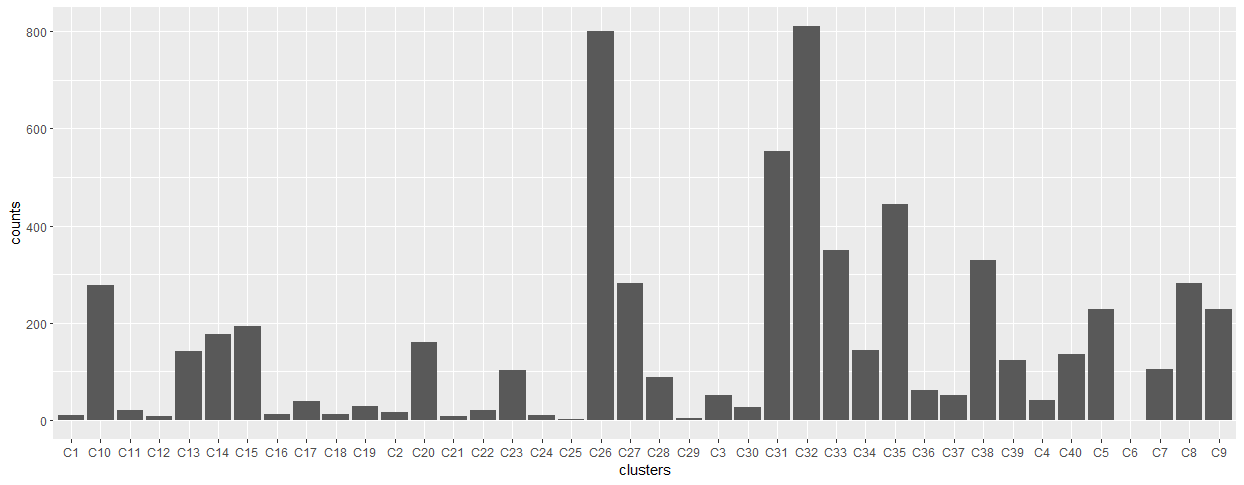
Figure 5.54: Figure 2. Histogram of graph count sums across all pieces of writing from writer 313
The idea is that the number of graphs that fall into each cluster is unique to an individual and is their “writer template”. Flash ID uses this feature as well.
5.3.7.2 Set Up
There are two groups when answering an open set question: the specific source and the alternative source. Say someone wrote a threatening letter and left it in a classroom. We also know the classroom had been cleaned that morning and the letter was not present, but it was after the students went to lunch. The specific source would be our suspect and the alternative source would be everyone else in the class present in those hours. We have three separate pieces of evidence then. u will denote unknown, s will denote specific source, and A will denote alternative source in general.
\(u_i\) is the vector of graph counts from the unknown document will be a vector of length 40 because we have 40 clusters (evidence obtained from crime scene)
\(s_j\) is the vector of graph counts from the control document will be a vector of length 40 because we have 40 clusters. Here we can have multiple documents . (material we gather from suspect)
\(A_{ij}\) is vector of graph counts in each of the 40 clusters from document j and alternative writer i in the population where I is number of different writers in alternative and j is number of documents.
\(H_p\): The QD was written by the suspect.
\(H_d\): The QD was written by someone else in the alternative source population
The specific source was modeled as a Dirichlet-Multinomial(\(θ_s\)) where \(θ_s\) is the rate of observing graphs in the clusters for the specific source. So each specific source will have 40 \(θ_s\). For the alternative source population, we use a hierarchical model where \(θ_a\) is drawn from a Dirichlet and then a Multinomial. To make the model simpler, we sum all the documents from the specific source into one row s. If s has 26 documents in it we take all the clusters in cluster 1 and sum them together and do that for all the clusters. The result is a vector of 40. We do a similar thing for \(A_{ij}\) where we take all the documents from the same writer and sum them together by clusters. The result is a single vector of 40 for each document.
5.3.7.3 The Model
\[M_s : s ∼ Fs(·|θs) = Dirichlet-Multinomial(θ_s)\] and
\[ M_a : B_i ∼ G(·|θ_a) = Dirichlet(θ_a) \] \[ A_i|B_i = b_i ∼ Fa(·|b_i, θ_a) = Multinomial(b_i)\] where marginally \[ A_i|θ_a ∼ Dirichlet-Multinomial(θ_a)\]
We make the same simplifications for the questioned documents, u, and sum them together by cluster.
\[M_p : u ∼ Dirichlet-Multinomial(θ_s) \] \[M_d : u ∼ Dirichlet-Multinomial(θ_a) \]
Then, we calculate the Bayes Factor using gamma priors (refer to Amy’s work).
## Error in knitr::include_graphics(c("images/handwriting/anyesha/bayesfactorformula.png")): Cannot find the file(s): "images/handwriting/anyesha/bayesfactorformula.png"Where \(n_p\) and \(n_d\) are the number of posterior samples and \(θ_s^{(i)}\) and \(θ_a^{(i)}\) are samples from the posterior distributions.
Above is called MC integration.We first set up our hierarchical model as shown above and get our posterior samples. Then, we set up our bayes factor calculation by inputting the unknown as the data and the posteriors as the parameter in our Dirichlet multinomial likelihood. We should get an out put of 15000 for both the specific and alternative source. We then add the outputs together and divide by 15000. Then divide the specific source by the alternative source and that should give you your Bayes factor.
From our hierarchical model, we get posterior samples that represent our cluster count data going through a prior and Dirichlet, multinomial. Then we input those thetas into the Dirichlet Multinomial distribution and divide by 15000. Originally, I had coded the pdf by hand as a function was difficult to find. In the end, we were able to find a function in the extraDistr package which drastically reduced computation times. We can directly do this because of math Danica did and this solves our integral.
A Bayes Factor of 1 indicates that the prosecution proposition and the defense proposition are equally favored. A Bayes Factor greater than 1 indicates that the \(H_p\) is favored and a Bayes Factor less than 1 indicates that the \(H_d\) is favored. In Gabrielle Collins and Danica Ommen’s, paper they only ran one simulation, so I will be running multiple.
We use writer 36 as our specific source. Every other writer in the data set is our alternative source, and we have two questioned documents, one from writer 36 and one from writer 71.
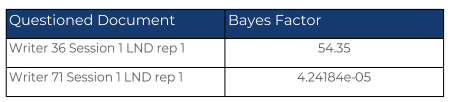
A Bayes Factor of 1 indicates that the prosecution proposition and the defense proposition are equally favored. A Bayes Factor greater than 1 indicates that the Hp is favored and a Bayes Factor less than 1 indicates that the Hd is favored. From the Bayes Factors shown in the Methods and Results section, we can conclude that our first questioned document did come from our specific source because it is greater than 1. The Bayes Factor for the second questioned document signifies that the questioned document is from an alternative source as it is a very small number. Since we know the true source is writer 36, these numbers represent the correct conclusion.
From here, I will be confirming these results and coding it to run on a loop to run multiple writers.
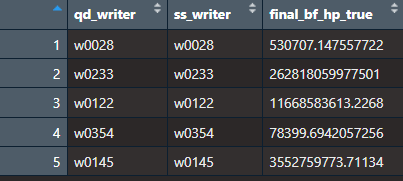
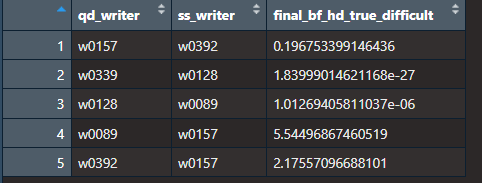
5.3.7.4 Calculating Bayes Factors for All Writers (actually it’s only 5 so far)
Now, the goal is to calculate Bayes Factors for all the writers. Here is how we are setting it up.
- We randomly select n writers. For testing purposes I chose n to be 5 (eventually we will do this with all the writers).
- We randomly choose an unknown/questioned document. We want to compare this unknown in three scenarios.
- One where the Hp is true and the unknown/qd comes from our specific source.
- One where the Hd is true so the unknown/qd comes from our alternative source but where it is easy to distinguish the writers.The idea is that we are randomly selecting writers and checking Bayes Factors for writers that are most similar to our unknown (kinda like a close non match)
- One where the Hd is true so the unknown/qd comes from our alternative source but where it is difficult to distinguish the writers.
To determine the easy and difficult case, we rank all of our writers by their Euclidean distance of the proportion of graphs (add each writers documents together then calculate proportion of graphs in each cluster). The one that is most similar to the unknown gets assigned to be our specific source and the rest of the writers get put in the alternative source for the hard case.The one that is least similar to the unknown gets assigned to be our specific source and the rest of the writers get put in the alternative source for the easy case.
- Then run through the Bayes Factor choosing an unknown from a different writer each time.
Here are the results:

5.4 Communication of Results
Presenting author is in bold.
5.4.1 Papers
“A Clustering Method for Graphical Handwriting Components and Statistical Writership Analysis”
- Authors: Nick Berry and Amy Crawford
- Submitted to The Annals of Applied Statistics in September 2019.
“A Database of Handwriting Samples for Applications in Forensic Statistics”
- Authors: Anyesha Ray, Amy Crawford, and Alicia Carriquiry
- Submitted to Data in Brief in October 2019.
“Bayesian Hierarchical Modeling for Forensic Handwriting Analysis”
- Authors: Amy Crawford, Alicia Carriquiry, and Danica Ommen
- In preparation for submission to PNAS.
5.4.2 Talks
“Statistical Analysis of Handwriting for Writer Identification”
- August 2019
- Authors: Amy Crawford, Nick Berry, Alicia Carriquiry, Danica Ommen
- American Society of Questioned Document Examiners (ASQDE) Annual Meeting in Cary, NC.
“A Bayesian Hierarchical Mixture Model with Applications in Forensic Handwriting Analysis”
- July 2019
- Authors: Amy Crawford, Nick Berry, Alicia Carriquiry Danica Ommen
- Joint Statistical Meetings (JSM) in Denver, CO.
“Forensic Analysis of Handwriting”
- July 2019
- Authors: Alicia Carriquiry, Amy Crawford, Nick Berry, Danica Ommen
- VI Latin American Meeting on Bayesian Statistics (VI COBAL), Lima, Peru.
“Exploratory Analysis of Handwriting Features: Investigating Numeric Measurements of Writing”
- February 2019
- Authors: Amy Crawford, Nick Berry, Alicia Carriquiry, Danica Ommen
- American Academy of Forensic Sciences (AAFS) Annual Meeting in Baltimore, MD.
“Toward a Statistical and Algorithmic Approach to Forensic Handwriting Comparison”
- August 2018
- Authors: Amy Crawford and Alicia Carriquiry
- American Society of Questioned Document Examiners (ASQDE) Annual Meeting in Park City, UT.
“A Bayesian Approach to Forensic Handwriting Evidence”
July 2018
- Authors: Amy Crawford and Alicia Carriquiry
Joint Statistical Meetings (JSM) in Vancouver, BC, Canada.
“Bringing Statistical Foundations to Forensic Handwriting Analysis”
- May 2018
- Authors: Amy Crawford and Alicia Carriquiry
- American Bar Association, 9th Annual Prescription for Criminal Justice Forensics Program in New York, NY.
5.4.3 Posters
“A Bayesian Hierarchical Model for Forensic Writer Identification”
September 2019
Authors: Amy Crawford, Alicia Carriquiry, Danica Ommen
10th International Workshop on Statistics and Simulation in Salzburg, Austria
1st Springer Poster Award
Click for Poster Image

Poster given at the 10th International Workshop on Simulation and Statistics
“Statistical Analysis of Handwriting”
- May 2019
- Authors: Amy Crawford and Nick Berry
- CSAFE Annual All-Hands Meeting in Ames, IA
“Statistical Analysis of Letter Importance for Document Examination”
- February 2018
- Authors: Amy Crawford and Alicia Carriquiry
- American Academy of Forensic Sciences in Seattle, WA
- YFSF Best Poster Award
(Presented AAFS 2018 Poster for a Second Time)
- May 2018
- Authors: Amy Crawford and Alicia Carriquiry
- CSAFE Annual All-Hands Meeting in Ames, IA
“Quantitative Support for Forensic Document Examination in an Open Set using Random Forests”
February 2021
Authors: Madeline Q. Johnson, Danica Ommen, and Alicia Carriquiry
American Academy of Forensic Sciences, Virtual
Click for Poster Image

Poster given at AAFS 2021 Meeting
“Relationship Between Handwriting Slant and Demographic Features”
February 2021
Authors: Anyesha Ray and Alicia Carriquiry
American Academy of Forensic Sciences, Virtual
Click for Poster Image
Poster given at AAFS 2021 and IAI 2021 Meeting
“Quantifying Bayes Factors for Forensic Handwriting Evidence”
February 2023
Authors: Anyesha Ray, Danica Ommen
American Academy of Forensic Sciences
Click for Poster Image

Poster given at AAFS 2023 Meeting
5.5 Deep Learning Methods
We are currently researching ways in which we can use convolutional neural networks (CNN) to classify pieces of handwriting by their author. Similar ideas have and are being used in applications to to face recognition and shoe print comparisons in forensics. Identifying key differences in particular features in handwriting authorship and other applications will help determine artchitectural advantages and disadvantages in different CNNs to optimize success in the classification of an author’s handwriting.
One potential approach we are investigating is using a Siamese neural network which uses the same weights and CNN architecture to train two images and output a metric noting their similarity. An outputted metric could be utilized to obtain a likelihood score that would then be used to classify similar images. With a focus on offline signatures, we are investigating the architectures of different CNNs used for other handwriting datasets to use as a baseline for constructing our own CNN to train and evaluate our handwriting datasets.
In constructing a CNN we consider the following processes used in previous research for offline signatures: Decorrelation, normalization, aggregation of local features, extraction of selected local versus global features.
We programmed neural networks using data sets in keras (MNIST,IMDB,Reuters) to gain an understanding of the fundamental process in the algorithms.
Currently implementing a version of the TinyResNet Siamese CNN architecture, which was the best performing CNN in the paper Siamese Convolutional Neural Networks for Authorship Verification by Du W., Fang M., Shen M. Fully scanned pages of handwritten were broken down into lines to be used as the data inputted in the model. First we will use the model on the IAM handwriting data set broken down by line. Consists of 13,353 isolated and labeled text lines.
We used the ResNet CNN architecture to train a model on the IAM dataset to classify writers on the images in our own database.
Working on preprocessing images to work with the ResNet architecture as images need to be grayscaled and scaled to be square images. Two methods are to add padding to the top and bottom of a scanned line image, or break up a line into smaller parts essentially tiling the original image.
Matched input scale for ResNet50 architecture with preprocessed images. Paired images to use as training data and used a binary 0 or 1 labeling system to classify pairs that were different and the same respectively. The input data takes a very large amount of memory so to work around this issue, I have currently randomly sampeld observations from the training and test set to train and evaluate the resnet50 model.
Forgy, E. (1965). Cluster Analysis of Multivariate Data: Efficiency vs. Interpretability of Classifications. Biometrics, 21:768–780.↩︎
Lloyd, S. (1982). Least Squares Quantization in PCM. IEEE Trans. on Information Theory, 28(2):129–137.↩︎
Gan, G. and Ng, M. K.-P. (2017). K-means clustering with outlier removal. Pattern Recog. Letters, 90:8–14.↩︎
Kokonendji, C. C. and Puig, P. (2018). Fisher Dispersion Index for Multivariate Count Distributions. Journal of Multivariate Analysis, v165 p180-193.↩︎