library(handwriter)
# view cluster fill counts for template training documents
template_data <- format_template_data(example_cluster_template)
plot_cluster_fill_counts(template_data, facet = TRUE)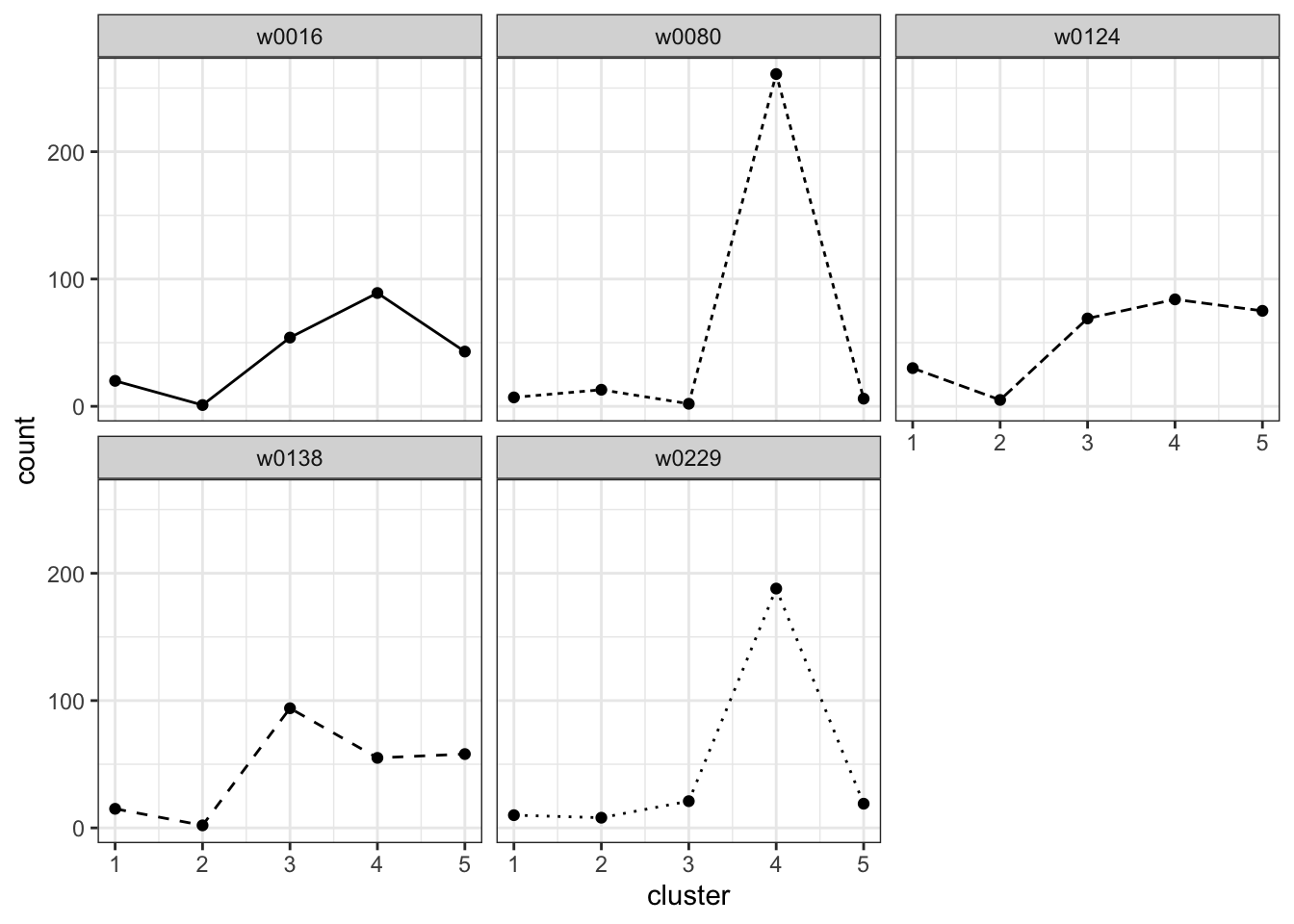
An example cluster template created with make_clustering_template(). The cluster template was created from handwriting samples "w0016_s01_pLND_r01.png", "w0080_s01_pLND_r01.png", "w0124_s01_pLND_r01.png", "w0138_s01_pLND_r01.png", and "w0299_s01_pLND_r01.png" from the CSAFE Handwriting Database. The template has K=5 clusters.
example_cluster_template
A list containing a single cluster template created by make_clustering_template(). The cluster template was created by sorting a random sample of 1000 graphs from 10 training documents into 10 clusters with a K-means algorithm. The cluster template is a named list with 16 items:
library(handwriter)
# view cluster fill counts for template training documents
template_data <- format_template_data(example_cluster_template)
plot_cluster_fill_counts(template_data, facet = TRUE)